
[CS231n] 4. Backpropagation and Neural Networks
업데이트:
Reference
-
Lecture 04 - ( Slide Link, ,Youtube Link )
이 포스팅은 CS231n의 4강을 요약한 글입니다 😊

지난 3강 에서는 Loss function과 Optimization에 대해 배웠습니다.
간단하게 정리하자면, Loss function은 data loss값과 regularization의 합으로 볼 수 있으며 정규화항은 우리의 모델이 얼마나 정규화된 모델인지를 표현해줍니다. SVM(Support Vector Machine) function은 위 슬라이드의 2번째 식으로 표현할 수 있으며 자세한 설명은 3강을 참고해주시면 좋을 것 같습니다 :)
우리는 최적의 Loss를 가지는 파라미터 weight를 구하는 것이 목적이며 그러기 위해서는 loss function의 weight에 관한 gradient를 구해야합니다.

optimization을 사용하여 최적의 gradient를 찾는 방식으로는 GD(Gradient Discent)가 있었습니다. 즉 경사가 하강하는 방향으로 반복해서 gradient를 구하다보면 최적의 기울기를 찾을 수 있게될 것입니다.

위와 같은 Numerical Gradient을 이용하여 gradient를 구할 수도 있지만 계산하기에 오랜 시간이 걸립니다.
1. Back-propagation
Analytic Gradient
- 수치적으로 그래디언트를 구하지 않고, 해석적으로 접근하여 gradient를 구하는 방식
Computational Graphs

- Computational graph를 사용해서 함수를 표현할 수 있게 되자 backpropagation이 가능해졌습니다.
- Back-propagation은 gradient를 얻기 위해 computational graph 내부의 모든 변수에 대해 Chain rule을 적용합니다.
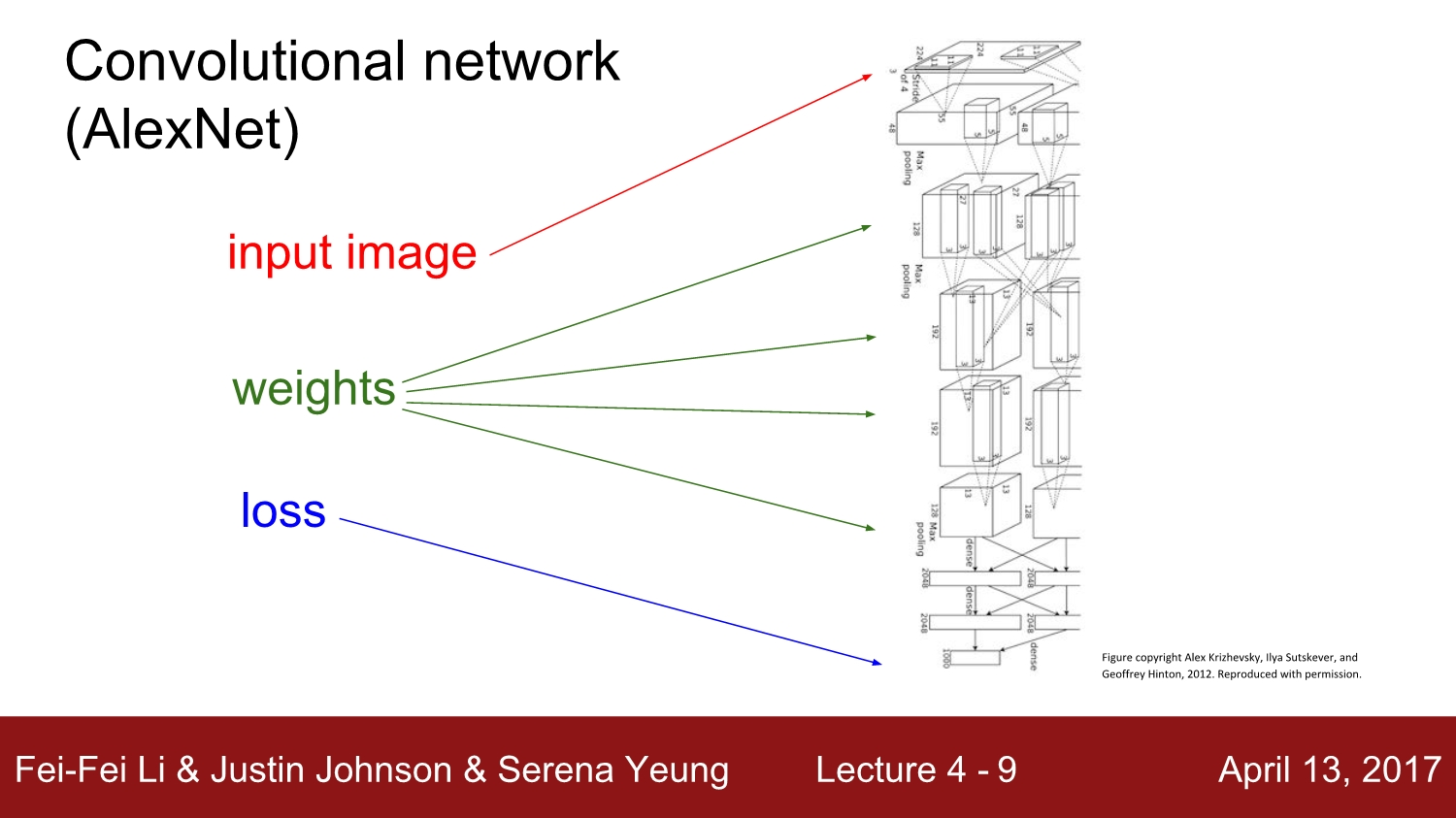

다음과 같은 복잡한 layer들을 가진 network에서도 computational graph를 사용하면 backpropagation을 할 수 있게 됩니다.




-
위의 슬라이드에서 확인할 수 있는 것처럼 Back-propagation은 chain-rule의 재귀적인 응용입니다.
-
Chain rule에 의해 우리는 뒤에서부터 계산을 시작합니다.
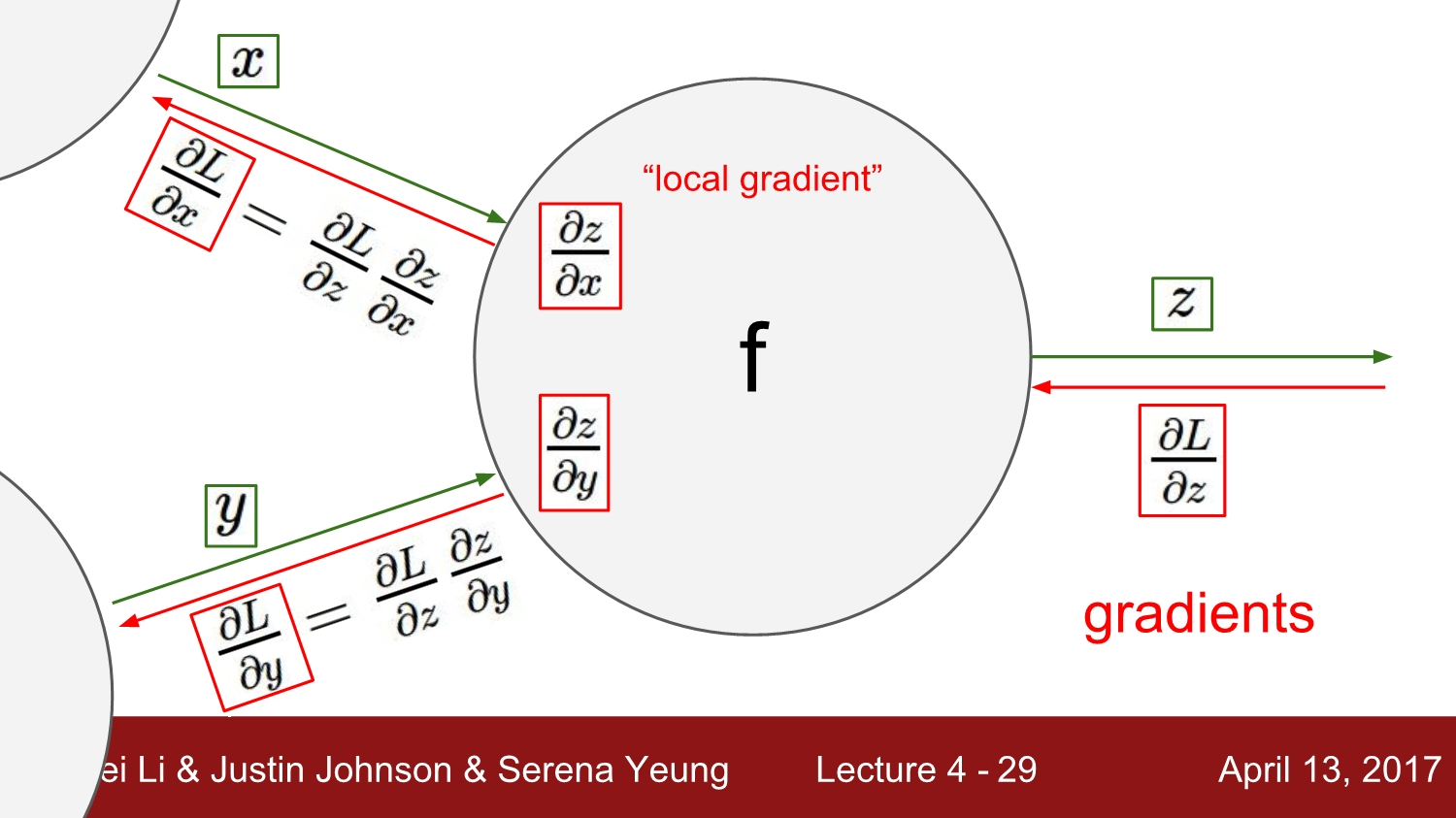
- chain rule을 사용하면 local gradient 값들을 사용해서 gradient를 구할 수 있습니다.
- chain rule에서는 항상 뒤쪽으로 gradient가 전파됩니다.
Chain Rule Example

f(w,x)라고 적혀있는 복잡한 exponential 식을 먼저 computational graph로 나타내면, 위의 그래프와 같은 node들이 그려집니다.



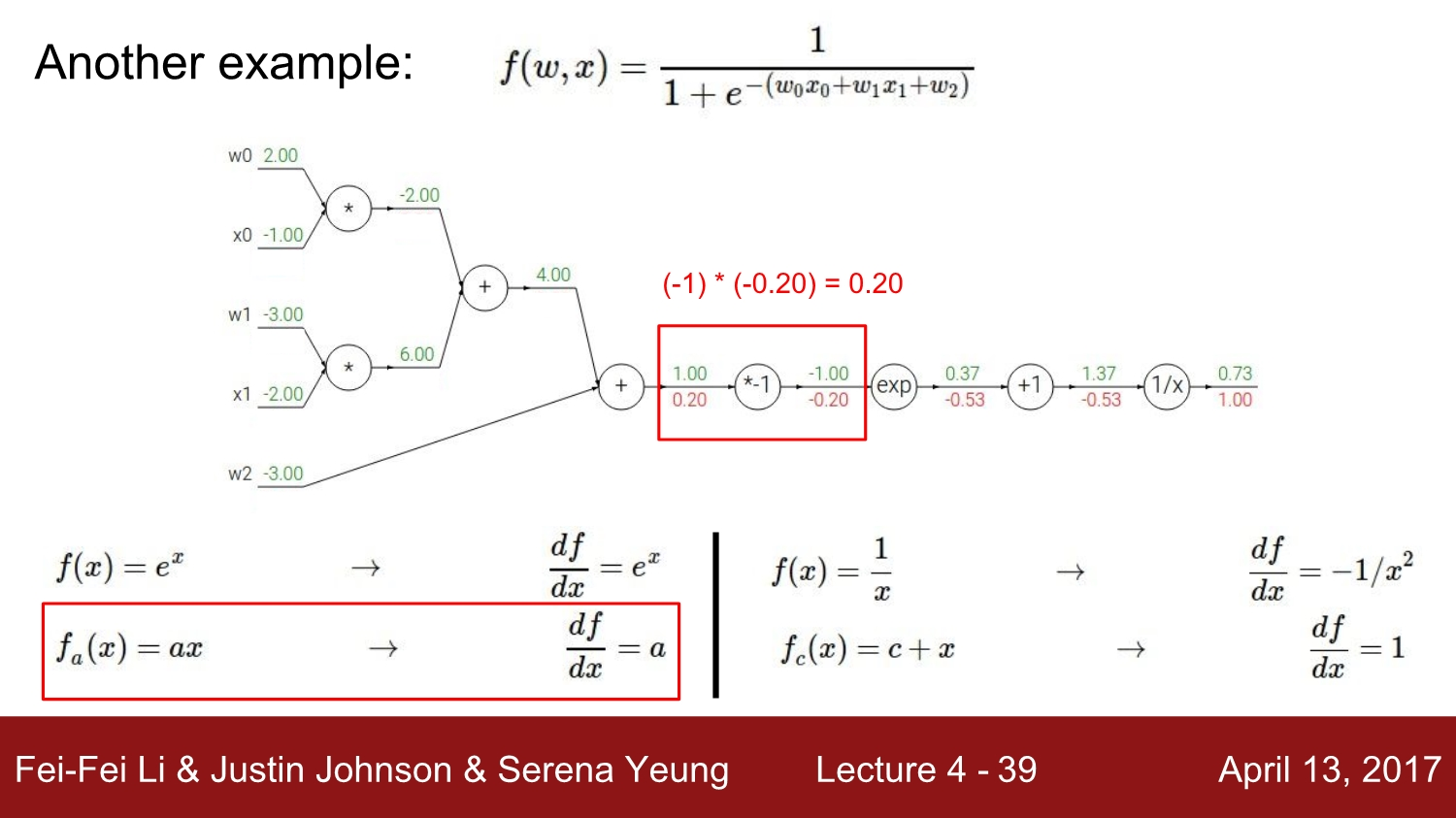


Chain Rule : local gradient와 upstream gradient를 통해 최종 gradient를 구할 수 있습니다.
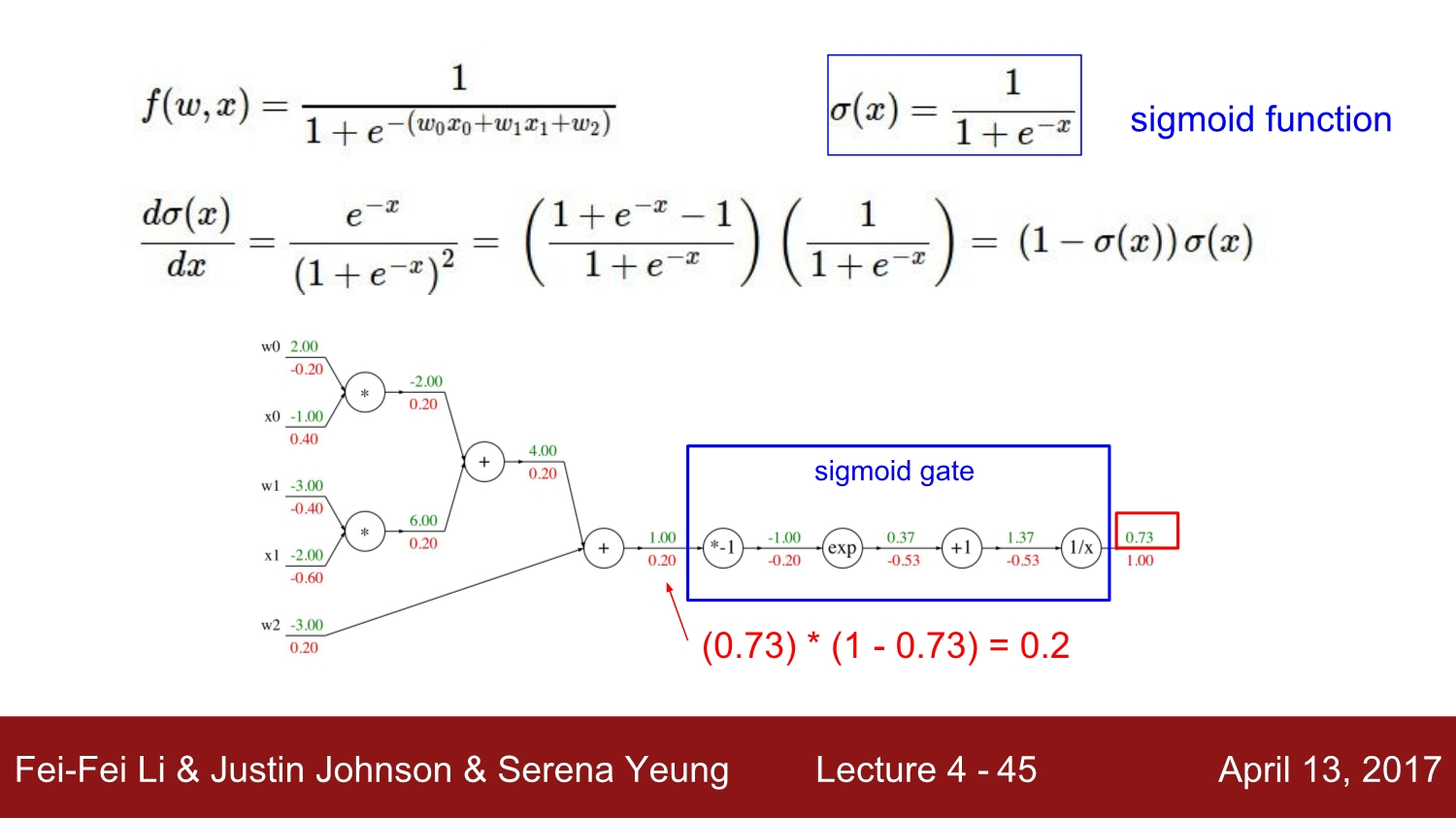
sigmoid function과 같은 복잡한 함수도 computational graph와 역전파를 통해 gradient를 계산하면 쉽게 기울기를 구할 수 있습니다.
Trade-off
각 node들의 식을 조금 더 복잡하게 만들면 node의 개수를 간소화할 수도 있습니다. 하지만, 그렇게 되면 node당 더 많은 계산이 필요해져서 연산에 좋지 않을 수도 있습니다.
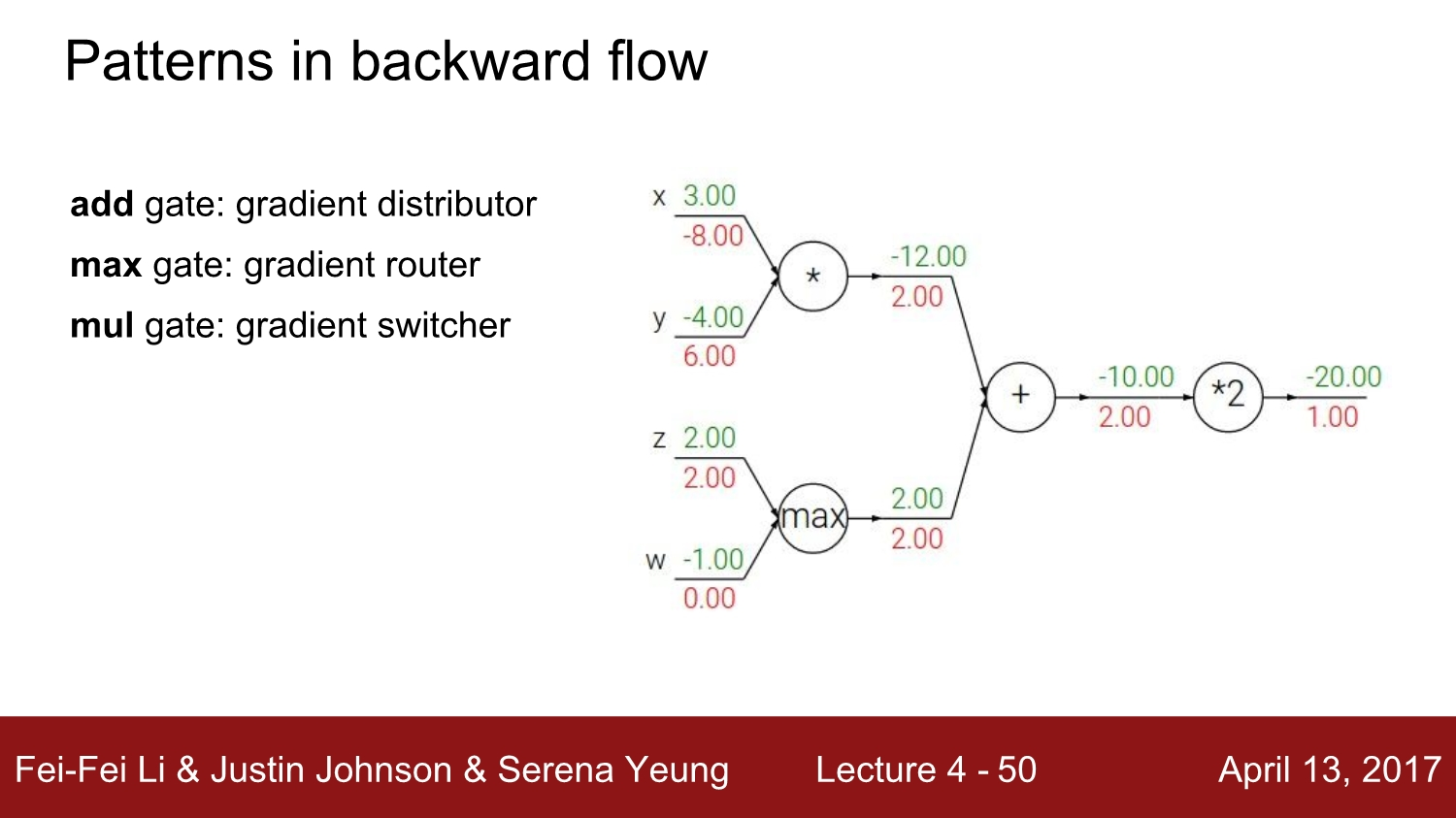
Patterns in backward flow
add gate: gradient distributormax gate: gradient router- 하나에는 전체 값, 나머지 하나에는 0이 들어감
mul gate: gradient switcher- upstream gradient를 받아 다른 branch의 값으로 scaling함
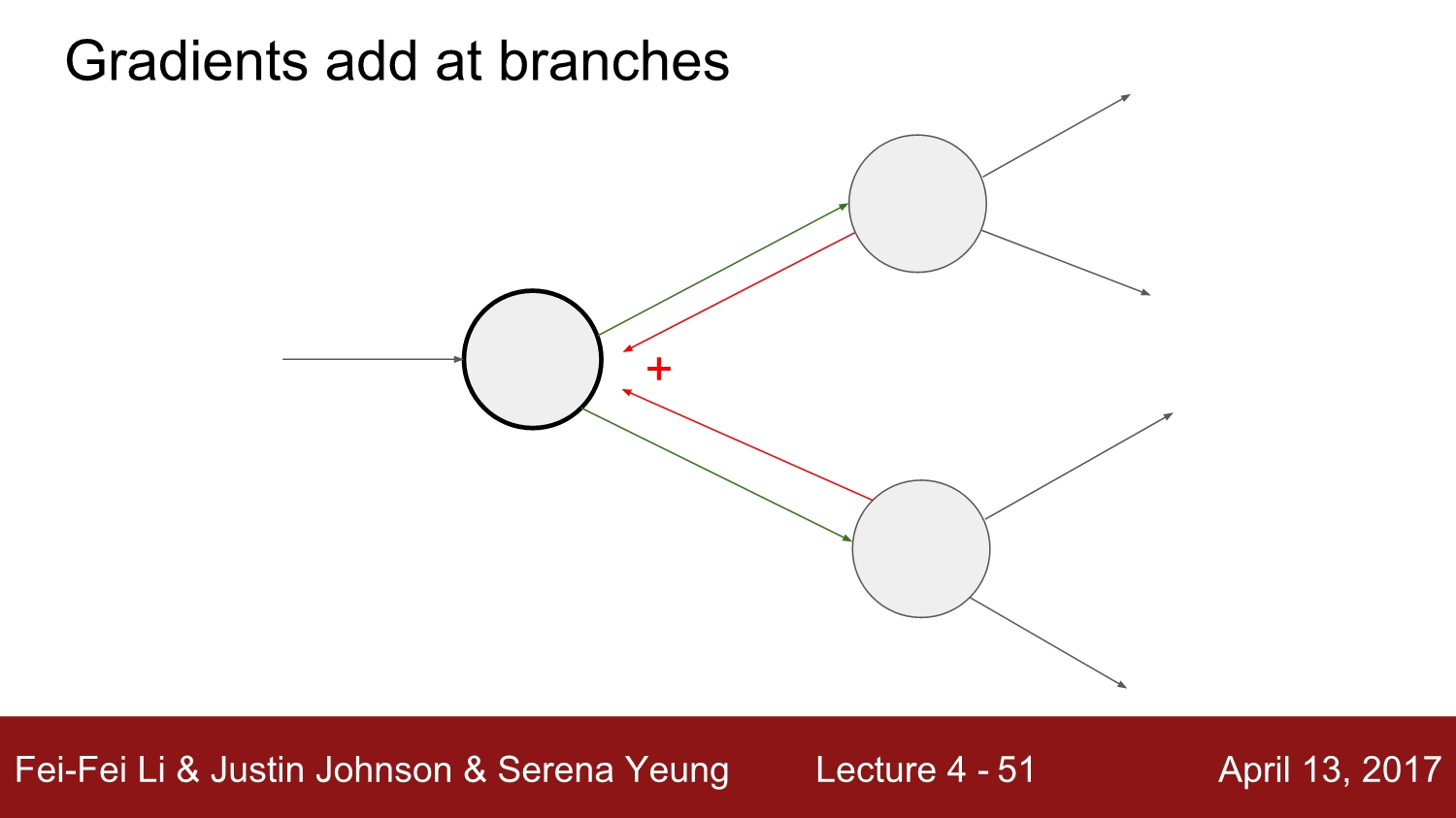
여러 개의 노드와 연결되어있는 하나의 노드가 있을 때 back-propagation에서는 upstream gradient를 합쳐줍니다. 이러한 경우에는 forward-propagation과 back-propagation이 서로 영향을 줍니다.
Gradients for vectorized code
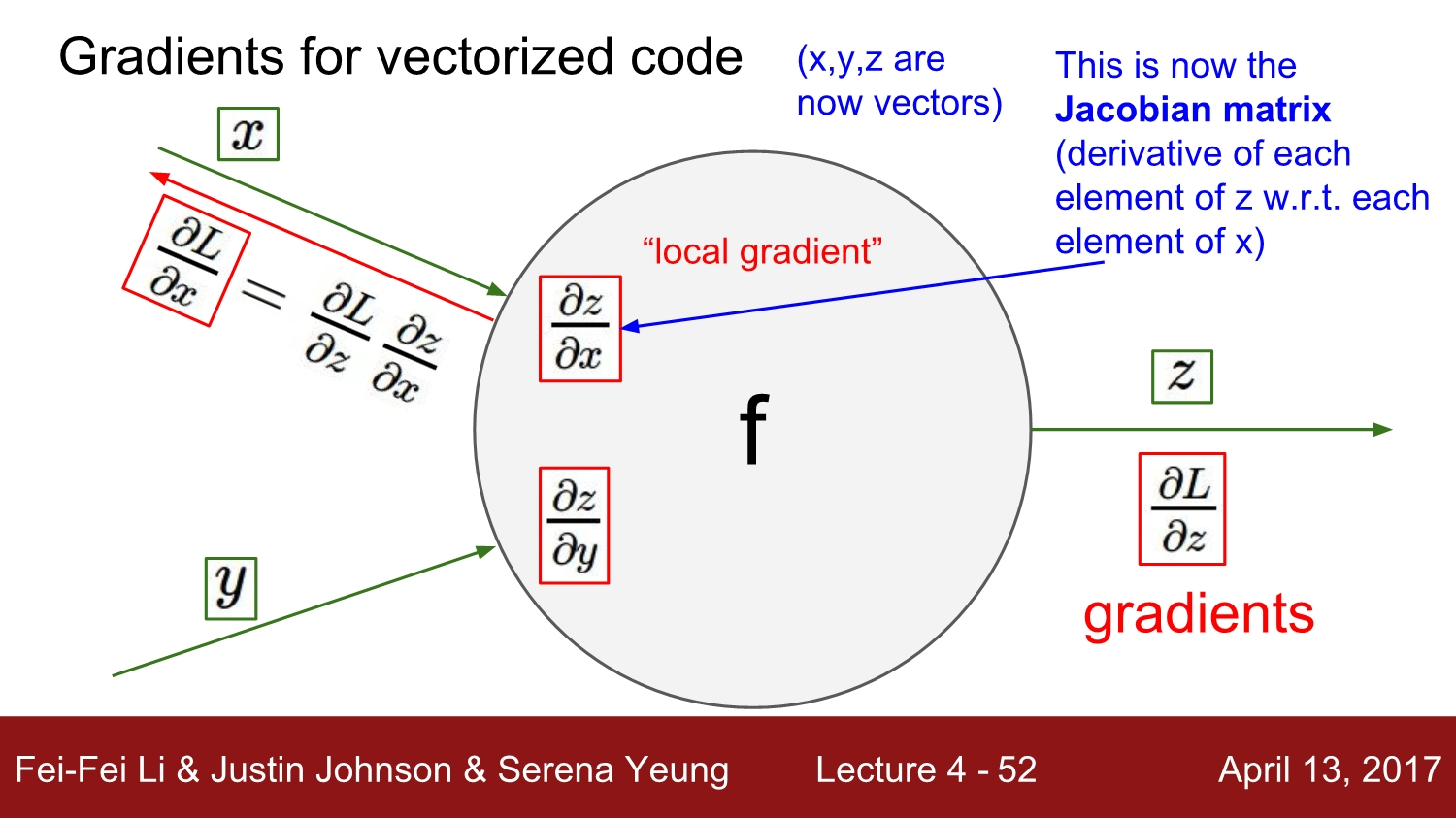
그동안은 scalar값에 대한 gradient에 대해 살펴봤다면, 이제부터는 vector에 대한 gradient를 살펴보겠습니다.
모든 것은 동일하지만, 이제는 gradient가 Jacobian 행렬이 됩니다.
-
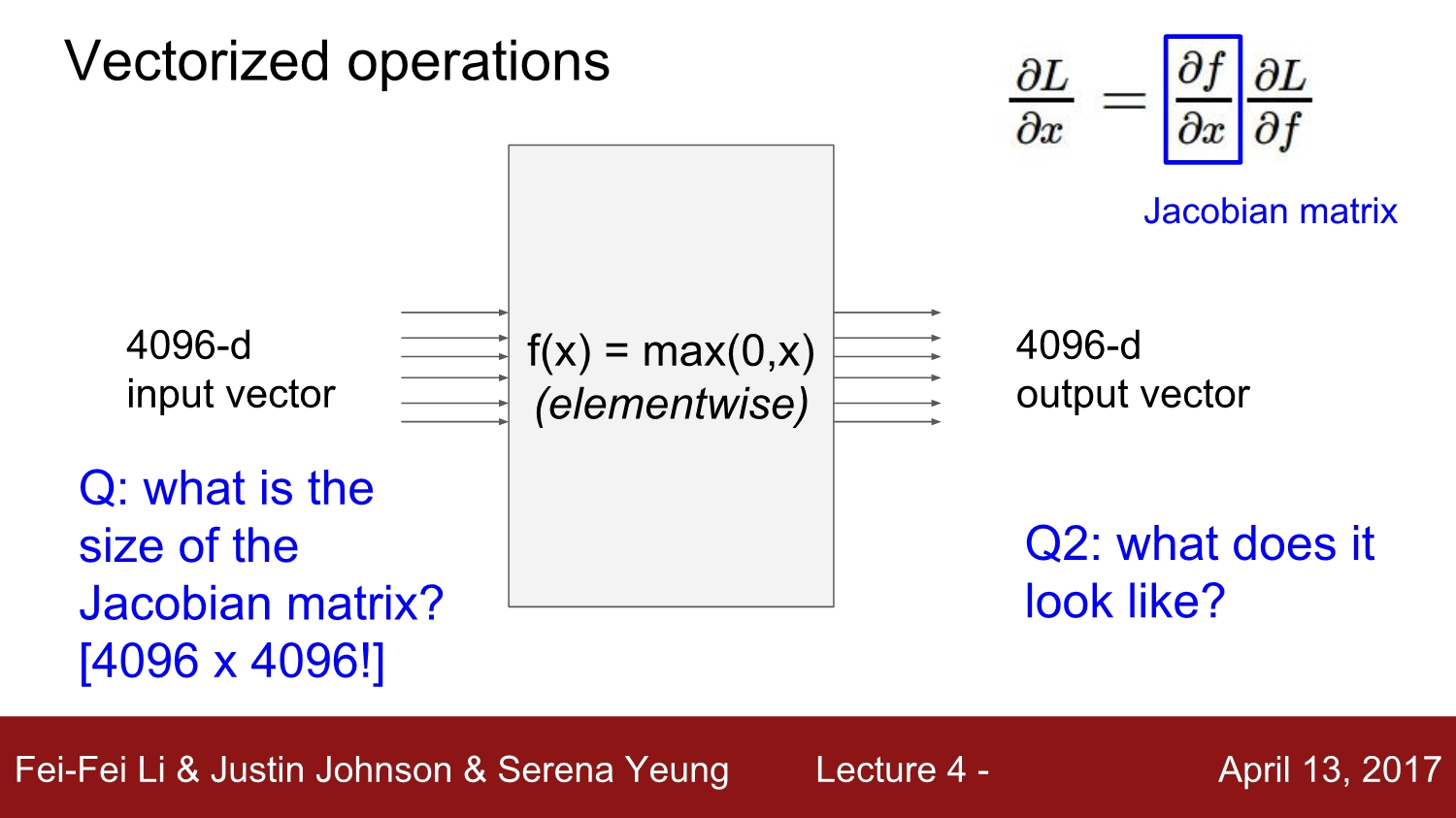
입력과 출력 모두 4096차원인 다음의 예제에서 Jacobian matrix의 크기는 4096^2 가 됩니다.
mini-batch를 가지고 훈련을 한다면 차원을 훨씬 더 커집니다.
- ex) 100개의 mini-batch -> Jacobian 은 [409600 x 409600]의 matrix
-
실제로는 이 모든 거대한 Jacobian 행렬에 대해 연산을 할 필요는 없습니다.
위의 연산은 element-wise이기 때문에 입력 벡터의 대각선 요소만이 출력에 영향을 줍니다. 즉, Jacobian matrix는 대각행렬이 됩니다.
Example


- Forward propagation을 한 후, L2-norm을 통해 최종 q값을 구하면
0.116이 됩니다.


Back-Propagation
- 2차원 vector
q에 대해 미분을 하면2q가 됩니다. - W의 gradient를 구하기 위해 chain-rule을 적용합니다.
2*q_i*x_j: [[ 0.44 * 0.2, 0.44 * 0.4 ], [0.52 * 0.2, 0.52 * 0.4]]

다음은 computational graph를 모듈화하여 코드로 구현한 것입니다. 각 노드를 local하게 보았고, upstream gradient들로 chain rule을 이용하여 local gradient를 계산하였습니다.
위의 코드의
- forward pass에서는 노드의 출력을 계산하는 함수를 구현하고
- backward pass에서는 gradient를 계산합니다.


Example : Caffe layers
- https://github.com/BVLC/caffe
 |
 |
⭐ Summary
- Neural Nets은 너무나도 크기 때문에 모든 parameter들의 gradient를 직접 계산하는 것은 불가능합니다.
- 그래서 backpropagation가 제안되었고, 역전파에서는 inputs, parameters, intermediates의 모든 gradient를 계산하기 위해 computational graph의 chain rule을 재귀적으로 실행합니다.
- 구현(implementation)은 graph structure를 따르며, 각 node들은
forward()/backward()API를 따릅니다. - forward : gradient 연산을 수행하고 그 과정에서 생성되는 intermediates를 메모리에 저장합니다.
- 이 값을 저장해야지 back-propagation이 가능해집니다.
- backward : chain rule을 적용하여 input에 대해서 gradient의 loss값을 계산합니다.
2. Neural Networks

그동안은 선형의 하나의 레이어만을 다뤘다면, 이제는 다양한 층의 뉴럴 네트워크에 대해 공부할 예정입니다. 간단하게 말하자면, 신경망은 함수들의 집합(class)으로 비선형의 복잡한 함수를 만들기 위해서는 간단한 함수들을 계층적으로 여러개 쌓아올려야 합니다.
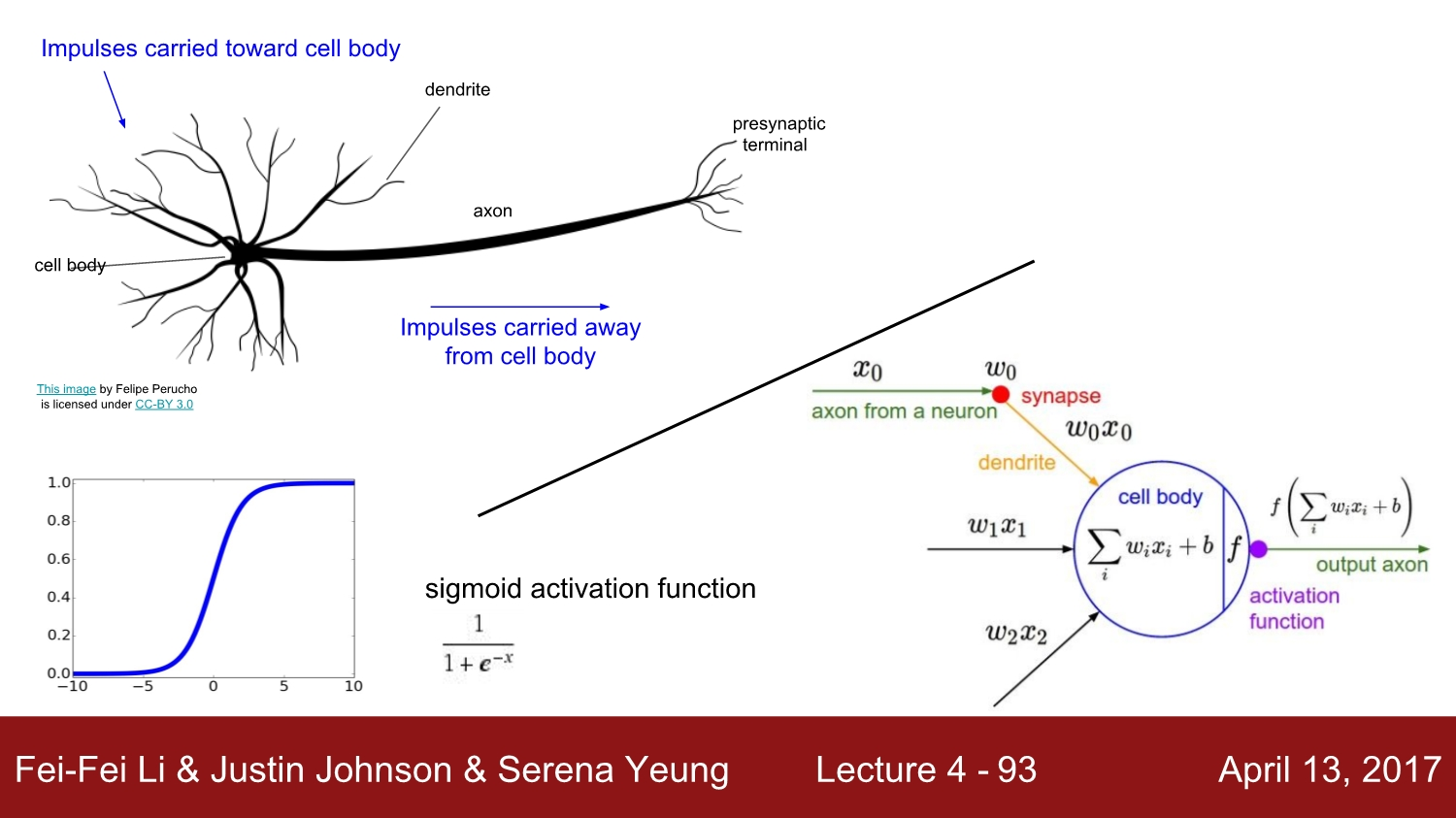

우리가 지금까지 배웠던 각 Computation node는 실제 뉴런이 작동하는 방식과 비슷하게 작동합니다.
마지막에 있는 activation function은 입력을 받은 후 나중에 출력이 될 하나의 숫자를 보여주는 함수입니다.
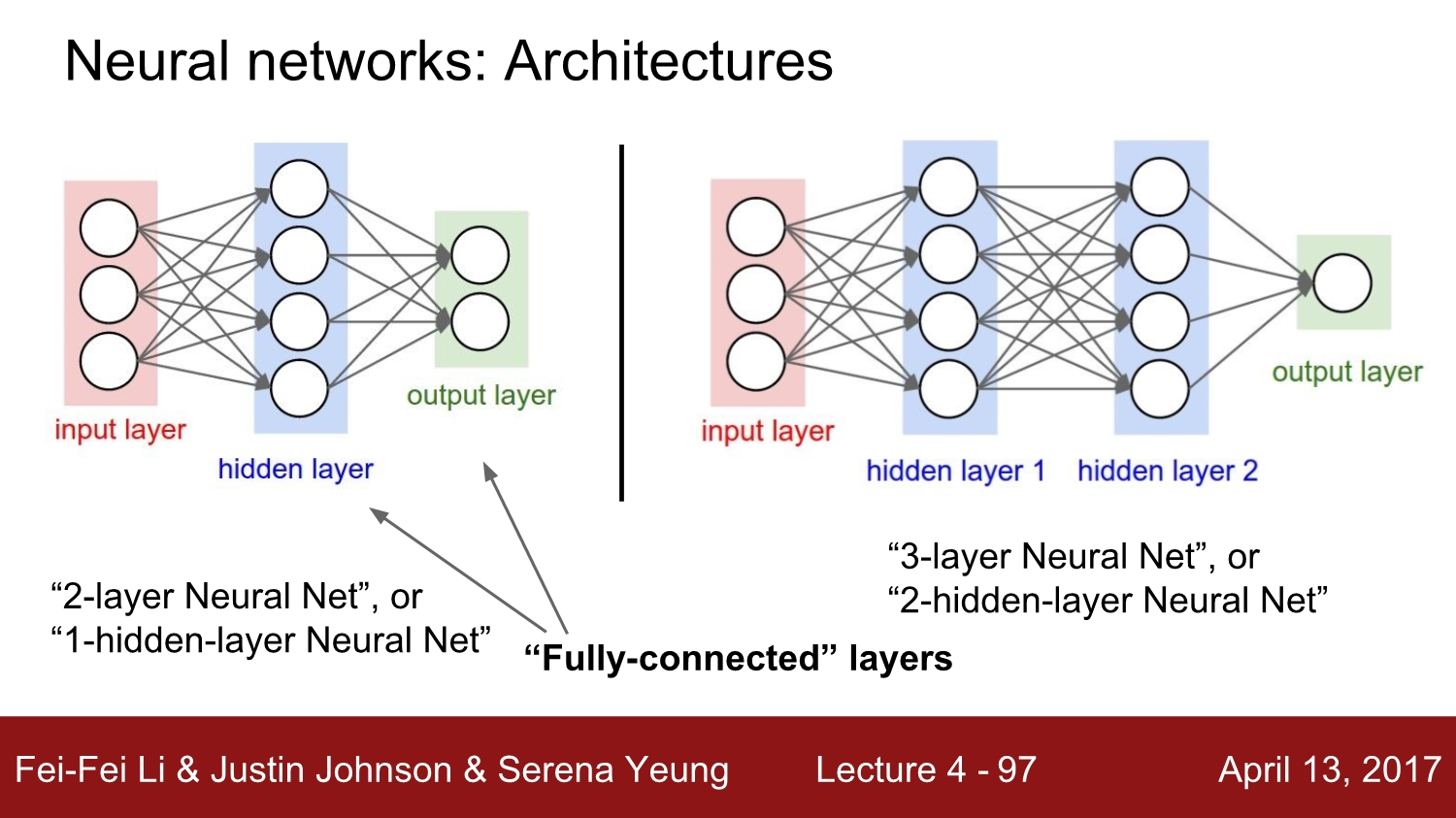
여지껏 배웠던 layer들은 Fully-connected되었다고 볼 수 있습니다. 즉, 한 layer의 모든 뉴런이 다음 layer의 모든 뉴런들과 연결되어있는 상태입니다.

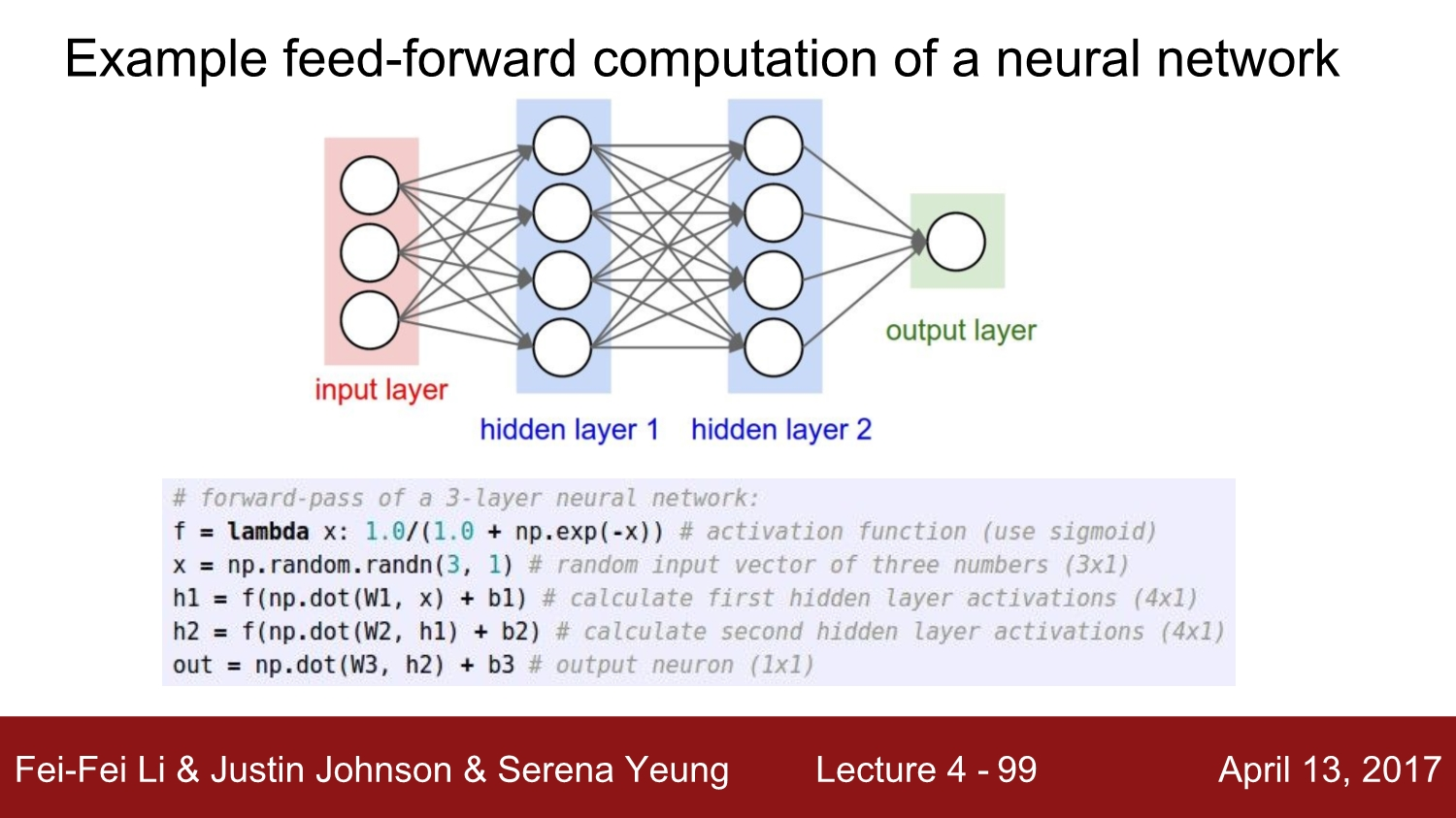
Summary
신경망이 무엇인지와 어떻게 뉴런들을 선형 layer와 fully-connected로 재배열하는지에 대해 배웠습니다.
- 가중치곱, activation function, max … 등등
위의 내용 중 궁금하신 점이 있으시다면 댓글로 남겨주세요 :)
감사합니다.
댓글남기기