
[Paper Review] MUNIT : Multi-Modal Unsupervised Image-to-Image Translation 간단한 논문 분석
업데이트:
✍🏻 이번 포스팅에서는 Unpaired dataset에 대해 Multimodal Image-to-Image translation를 하는 MUNIT에 대해 알아본다.
-
Paper : [MUNIT] Multi-Modal Unsupervised Image-to-Image Translation (ECCV 2018 / Xun Huang, Ming-Yu Liu, Serge Belongie, Jan Kautz)
1. Introduction

기존의 Multimodal Image-to-Image translation은 paired dataset에 대해 학습을 했다면(ex, BicycleGAN), MUNIT은 Unpaired dataset에 대해 unsupervised Image-to-Image translation을 수행한다.
기존의 모델들은 Source domain의 이미지가 주어졌을 때, 이에 상응하는 target domain의 Conditional Distribution을 deterministic one-to-one mapping로 구했기 때문에 다양한 output 이미지를 생성하지 못했다. 본 논문의 Multimodal Image-to-Image translation는 Source domain에 상응하는 target domain의 Multimodal Conditional Distribution을 학습하는 것이 목표이다.
MUNIT의 큰 흐름은 다음과 같다. (1) 이미지를 우선 content code와 style code로 decompose한다.

- content code 는 domain-invariant(domain-shared)한 이미지의 attribute에 대한 정보를 담고 있는 code다. 모든 domain의 이미지들은 content space $\mathcal{C}$ 를 공유한다.
- style code 는 domain-specific 한 이미지의 style에 대한 정보를 담고 있는 code로, 각 domain $\mathcal{X_i}$ 들의 style space $\mathcal{S_i}$ 는 각각 다르다.
(2) 이후 이미지의 target domain에서 sampling된 random style code와 source domain의 content code를 결합하여 새로운 이미지를 생성한다.

😉 이 연구를 발전시킨 연구가 styleGAN !
2. Model

MUNIT의 Image-to-Image Translation는 encoder-decoder를 통해 이루어진다.
예를 들어 $x_{1} \in \mathcal{X}{1}$ 의 이미지를 $\mathcal{X}{2}$ domain으로 변환하고자 할 때,
-
auto-encoder를 통해 각 이미지를 content code $c_i$와 style code $s_i$로 변환한 후 \(\left(c_{i}, s_{i}\right)=\left(E_{i}^{c}\left(x_{i}\right), E_{i}^{s}\left(x_{i}\right)\right)=E_{i}\left(x_{i}\right)\)
-
$G_2$를 이용하여 output image를 생성한다. \(x_{1 \rightarrow 2}=G_{2}\left(c_{1}, s_{2}\right)\)
2.1 Loss function
2.1.1 Bidirectional Reconstruction Loss
(1) Image Reconstruction : image -> latent -> image
- Figure2의 (a)

(출처) 네이버 AI 랩, 최윤제 연구원님 발표자료
\[\mathcal{L}_{\mathrm{recon}}^{x_{1}}=\mathbb{E}_{x_{1} \sim p\left(x_{1}\right)}\left[\left\|G_{1}\left(E_{1}^{c}\left(x_{1}\right), E_{1}^{s}\left(x_{1}\right)\right)-x_{1}\right\|_{1}\right]\](2) Latent Reconstruction : latent -> image -> latent
- Figure2의 (b)
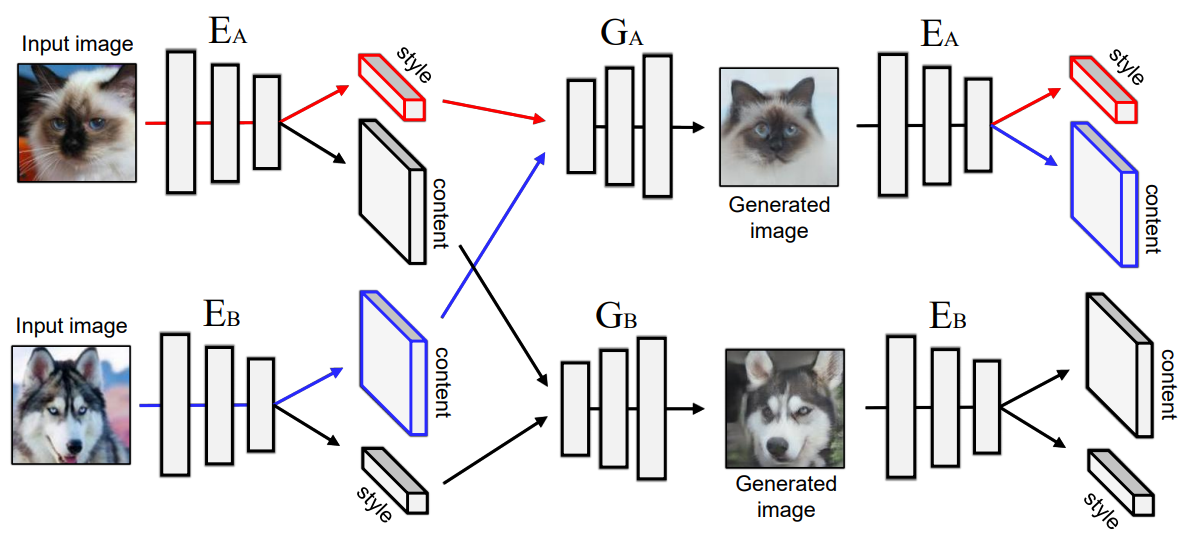

(출처) 네이버 AI 랩, 최윤제 연구원님 발표자료
- Content Reconstructive Loss
- source image의 attribute을 학습하기 위한 Loss
- Style Reconstructive Loss
- image의 style을 학습시키기 위한 Loss
2.1.2 Adversarial Loss
\[\mathcal{L}_{\mathrm{GAN}}^{x_{2}}=\mathbb{E}_{c_{1} \sim p\left(c_{1}\right), s_{2} \sim q\left(s_{2}\right)}\left[\log \left(1-D_{2}\left(G_{2}\left(c_{1}, s_{2}\right)\right)\right)\right]+\mathbb{E}_{x_{2} \sim p\left(x_{2}\right)}\left[\log D_{2}\left(x_{2}\right)\right]\]2.1.3 Total Loss
\(\begin{array}{l} \min _{E_{1}, E_{2}, G_{1}, G_{2}} \max _{D_{1}, D_{2}} \mathcal{L}\left(E_{1}, E_{2}, G_{1}, G_{2}, D_{1}, D_{2}\right)= \\ \mathcal{L}_{\mathrm{GAN}}^{x_{1}}+\mathcal{L}_{\mathrm{GAN}}^{x_{2}}+\lambda_{x}\left(\mathcal{L}_{\mathrm{recon}}^{x_{1}}+\mathcal{L}_{\mathrm{recon}}^{x_{2}}\right)+ \\ \lambda_{c}\left(\mathcal{L}_{\mathrm{recon}}^{c_{1}}+\mathcal{L}_{\mathrm{recon}}^{c_{2}}\right)+\lambda_{s}\left(\mathcal{L}_{\mathrm{recon}}^{s_{1}}+\mathcal{L}_{\mathrm{recon}}^{s_{2}}\right) \end{array}\)
2.2 Encoder-Decoder

MUNIT은 auto-encoder의 구조를 따르며, content encoder, style encoder, join decoder, 세가지의 subnetworks로 구성되어있다.
(1) Content Encoder
- 여러개의 strided convolution layers를 통해 input을 downsampling
- residual block
- 모든 conv layer에는 Instance Normalization(IN)을 적용
(2) Style Encoder
- 여러개의 strided convolution layers를 통해 input을 downsampling
- global averge pooling layer나 FC layer를 추가적으로 사용해서 spatial한 정보들을 최대한 없애고자 함
- (1)과 달리 IN을 사용하면 style information이 사라지므로 style encoder에서는 IN을 적용 X
(3) Decoder
- AdaIN(Adaptive Instance Normalization) 사용 \(\operatorname{AdaIN}(z, \gamma, \beta)=\gamma\left(\frac{z-\mu(z)}{\sigma(z)}\right)+\beta\)
- 여러개의 upsampling + conv layer를 이용하여 reconstruction
3. Experiments



4. Opinion
😊 MUNIT은 Multimodal Image-to-Image Translation의 baseline이 되는 논문이다. stylegan을 비롯한 다양한 image-to-image translation 논문들과 비슷한 logic이 많아 읽기 쉬웠던 것 같다.
댓글남기기