
GAN Inversion / Encoder : Image2stylegan, IDInvert, pSp, e4e
업데이트:
StyleGAN
😎 StyleGAN Posting
[Paper Review] StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks 논문 분석[Paper Review] StyleGAN2 : Analyzing and Improving the Image Quality of StyleGAN 논문 분석StyleGAN2-ADA: Training Generative Adversarial Networks with Limited Data#01#02
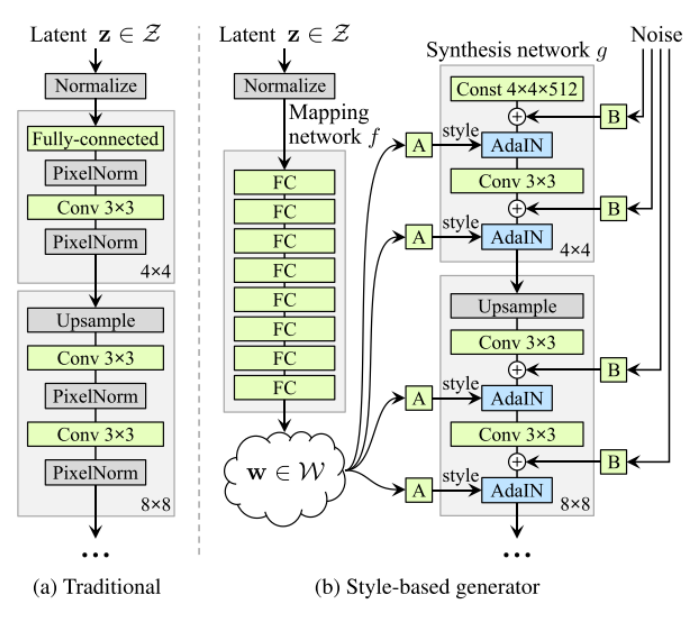
StyleGAN은 standard Gaussian latent space $Z$가 아니라 learnt intermediate latent space $W$를 사용하여 이미지를 생성. $W$는 $Z$에 비해 disentanglement하기 때문에 이를 활용하면 이미지 조작이 쉬움.
최근에는 StyleGAN의 이러한 성질을 이용하기 위해 실제 이미지를 $W$로 inversion한 후, latent manipulation을 통해 이미지를 조작하려는 시도가 많아짐 (Image Editing)
- GAN Inversion
- Latent space manipulation
GAN Inversion
Inversion: Image → style code $w \in W$ ⭐️ (1) reconstruction (2) editability (latent manipulation → meaningful image editing)
Method
- Latent Optimization
- Image2stylegan: How to embed images into the stylegan latent space?
- Image2stylegan++: How to edit the embedded images?
- Encoder
- ALAE: Adversarial latent autoencoders (github)
- pSp: Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
- Hybrid approach
- stylegan-encoder
- IdInvert : In-Domain GAN Inversion for Real Image Editing
1. Image2StyleGAN
- Paper : Image2stylegan: How to embed images into the stylegan latent space? (ICCV 2019 / Rameen Abdal, Yipeng Qin, Peter Wonka)
Image2StyleGAN : extended latent space $W+$를 제안
conventional StyleGAN:
512-dim$z \in Z=\mathcal{N}\left(\mu, \sigma^{2}\right)$ →8 MLP→512-dim$w \in \mathcal{W} \subsetneq \mathbb{R}^{512}$- 기존의 StyleGAN은 하나의 style vector $w$를 여러 AdaIN block의 input으로 사용하였다면, Image2StyleGAN에서는 extended latent space $W+$를 제안하여
18 different 512-dim w vector를 사용 : $w \in \mathcal{W}^k \subsetneq \mathbb{R}^{k \times 512}$- $\mathcal{W+}$에서 (1) early layers는 layout을 control, (2) middle layers는 object를 control, (3) late layers은 final rendering을 control함.
Latent Optimization : select a random initial latent code → optimize it using gradient descent
2. IDInvert
-
Paper : In-Domain GAN Inversion for Real Image Editing (ECCV 2020 / Jiapeng Zhu, Yujun Shen, Deli Zhao, Bolei Zhou)
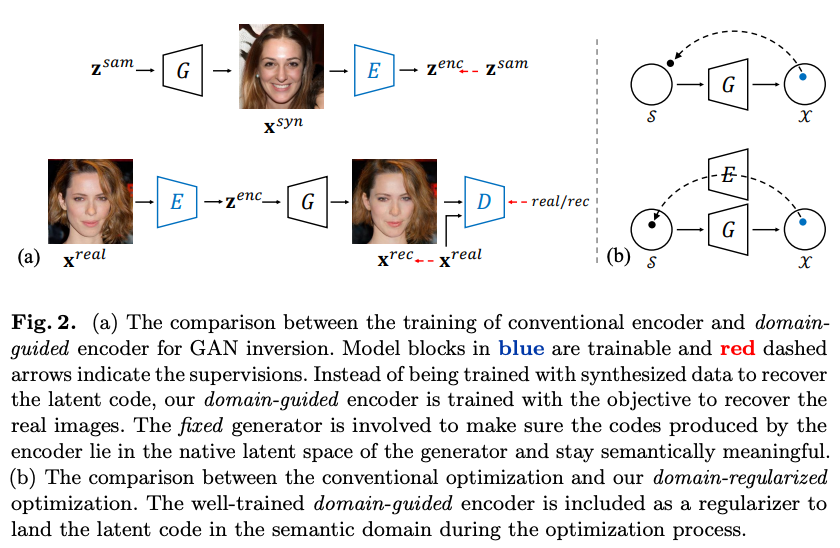
- 기존 모델의 문제점 : 기존의 Inversion model들은 이미지를 단순히 reconstruction하는 것이 목적이어서 inverted code가 original latent space의 semantic domain 내에 있지 않았음.
In-domain GAN inversion : image의 reconstruction은 당연히 잘되며 inverted code가 riginal latent space의 semantic domain 내에 있기 때문에 이를 조작함으로써 image editing이 가능해짐
(1) domain-guided encoder : image를 in-domain latent space로 inversion (2) domain-regularized optimization : inverted code를 optimize해서 target image로의 recon이 더 잘되도록 함
real image → Encoder → extended latent space $W+$ (
18개의 512-dim w vector→ image optimization
3. pSp : pixel2Style2pixel
- Paper : Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation (CVPR 2021 /Jiapeng Zhu, Yujun Shen, Deli Zhao, Bolei Zhou)
- Github

(1) StyleGAN encoder
- real image를 $W+$ latent domain으로 encoding. (추가적으로 optimization 과정이 필요 없음)
- Encoder는 Feature Pyramid Network 구조를 따름.
(2) Image-to-Image translation
- 기존의 sota model보다 더 좋은 성능을 냄.
- simplification of the training process : pretrained StyleGAN Generator를 이용하므로 adversarial 하게 학습할 필요 없음(학습과정에서
D필요 X)- 다양한 multi-modal I2I translation 가능
4. e4e : Encoder for Editing
- Paper : Designing an Encoder for StyleGAN Image Manipulation (arxiv 2021 /Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, Daniel Cohen-Or)
- GAN Inversion : reconstruction, editability ⭐️
- Reconstruction : 2가지로 평가되어야함
- distortion : $\mathbb{E}{x \sim p{X}}[\Delta(x, G(w)]$
- perceptual quality : $\Delta(x, G(w)$
- Editablity
- latent space의 disentanglement
- image editing 후에도 perceptual quality가 높게 유지되는 것이 중요
| notation | latent space |
|---|---|
 |
 |

E4E : ecoder-based method → (1) inference time 빠름 (2) encoder가 CNN으로 되어있기 때문에 image editing에 좋음
approach for getting closer to $\mathcal{W}$
- Minimize Variation
- encoder는 single $\mathcal{W_}$을 추론하도록 훈련. 이후 network에서 $\Delta_i$를 학습하여 $\mathcal{W_}$에서 $\mathcal{W_*^k}$로 확장
- $L_2$ delta-regularization loss
- Minimize Deviation From $\mathcal{W^k}$ : encoder는 $\mathcal{W^k}$과 close한 $\mathcal{W_*^k}$을 추론하도록 훈련.
댓글남기기