
2021 생성모델 연구 동향 및 주요 논문 / AI Content Creation: Deep Generative Model
업데이트:
Interpreting Deep Generative Models for Interactive AI Content Creation by Bolei Zhou 영상을 보고 리뷰한 글입니다.
Progress for Image Generation
GAN-based Model

GAN: Generative Adversarial Networks (NIPS 2014) : arxiv, reviewDCGAN: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (ICLR 2016) : arxiv, reviewPG-GAN: Progressive Growing of GANs for Improved Quality, Stability, and Variation (ICLR 2018) : arxiv, reviewBigGAN: Large Scale GAN Training for High Fidelity Natural Image Synthesis (2019) : arxivStyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks (CVPR 2019) : arxiv, reviewStyleGAN v2: Analyzing and Improving the Image Quality of StyleGAN (2020) : arxiv, reviewStyleGAN-ADA: Training Generative Adversarial Networks with Limited Data (NeurlPS 2020) : arxiv : review #01, #02

NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (ECCV 2020) : arxiv, project page- 여러 각도에서 촬영한 이미지들을 input으로 사용하여 새로운 view에서의 이미지를 만들어낸 모델
DALLE: Zero-Shot Text-to-Image Generation (ICML 2021) : arxiv, project pageText-to-Image Generation: OpenAI에서 공개한 모델로, text로 부터 이미지를 생성하는 모델 (transformer 기반)
Generative Adversarial Networks (GANs)

GAN: Generative Adversarial Networks (NIPS 2014) : arxiv, review- Ian-Goodfellow가 2014년에 공개한 모델로, 현재 대부분의 생성모델은 GAN의 network를 따르고 있음
Generator가 random vectorz로 부터 fake imageG(z)를 생성하면,Discriminator가 생성된 이미지가 진짜인지 가짜인지를 판별G와D가 싸우면서 학습하는 방식
How to Steer Neural Image Generation?

침대라는 이미지를 생성한다고 할때, 다양한 스타일의 침대나 다양한 각도에서 찍은 이미지를 생성하려면 어떻게 할까? → latent space나 conv filter를 조절 !

- Deep Generative Model은 Latent vector를 Convolutional Neural Network의 input으로 넣어 이미지를 생성
- 이미지의 주요 feature는 (1) Conv filters와 (2) latent space에서 결정됨
- 이 두가지의 요소에 따라 이미지가 어떻게 변화하는지를 이해한다면, 원하는 대로 이미지를 editing할 수 있을 것 !
Interpretation Approaches
- Supervised Approach : Label이나 훈련된 classifier로 Generator가 이미지를 잘 생성하고 있는지에 대한 ground truth를 제공하는 방식
- Unsupervised Approach : Label이나 훈련된 classifier없이 Generator를 학습
- Zero-Shot Approach : align language embedding with generative representations
1. Supervised Approach
Use labels or trained classifiers to probe the representation of the generator
1.1 Manipulating Conv filters
1.1.1 GAN Dissection

GAN Dissection: Visualizing and Understanding Generative Adversarial Networks (ICLR 2019) : arxiv, project page- Supervised Aprroach의 초기 연구
- GAN의 feature map과 이미지의 semantic segmentation이 matching되도록 학습
- 특정 feature map이 이미지 내에 어떤 object를 생성하는지를 연구하였음.
- interactive하게 이미지 내의 특정 object를 지울 수도 있고, 생성할 수도 있음.

예를 들어, 교회 이미지가 생성됐을 때
- 같은 object끼리 grouping(b). (ex. 나무는 나무끼리 grouping)
- object unit의 featuremap이 semantic segmentation과 match되도록 해야함.
- 이미지에서 특정 object를 사라게 하거나(c), 다시 생성할 수 있어야 함(d)
- Generator가 배경과 object 사이에 관계를 이해해야함 (ex. 건물에 문은 생길 수 있어도, 건물에 구름이나 나무가 있으면 안됨)
1.2 Manipulating Latent Space
각각의 Conv Filter이 어떤 object를 생성하는지를 찾은 후에 이를 editing하는 방식도 있지만, latent space가 disentangle하다면 이를 조절함으로써 이미지를 editing하는게 더 수월함
1.2.1 HiGAN

HiGAN: Semantic Hierarchy Emerges in Deep Generative Representations for Scene Synthesis (IJCV 2020) : arxiv, project page- 훈련된 classifier로 생성된 이미지의 object들을 분류한 후(category, attribute), 각각의 object들이 latent vector와 어떻게 연관이 되어있는지를 학습 → 특정 feature를 생성하는 latent vector를 조절하면서 image editing

Result

1.2.2 InterFaceGAN

InterFaceGAN: Interpreting the Latent Space of GANs for Semantic Face Editing (CVPR 2020) : arxiv, project pageHiGAN모델을 연구한genforce에서 발표한 모델- latent vector의 특정 방향이 특정 attribute를 조절함을 찾은 후, latent manipulation을 통해 face image를 editing하는 모델 (PGGAN, StyleGAN 등에 접목 가능)
1.2.3 StyleFlow

-
StyleFlow: Attribute-conditioned Exploration of StyleGAN-Generated Images using Conditional Continuous Normalizing Flows (ACM TOG 2021) : arxiv, project page - StyleFlow: StyleGAN + Flow-based conditional model
- 17가지의 face-attribute에 관여하는 특정 latent vector를 찾는 모델
attribute classifier를 사용하여 StyleGAN을 통해 생성된 이미지의 attribute들을 뽑은 후, 이를 label로 사용하여 conditional 하게 이미지 editing에 관여하는 latent vector를 학습하여 찾음
- 기존의 latent mainpulation model들은 linear하게 latent vector를 수정함으로써 이미지를 editing 했다면, 이 모델은 non-linear 하게 latent vector를 조절
- 이 모델은 두가지 task를 할 수 있음 : (1) attribute-conditioned sampling: target attribute를 가지고 있는 high-quality 이미지를 생성 (2) attribute-controlled editing: real image를 target attribute를 가진 이미지로 editing

- ⭐️ contribution : (1) 기존의 모델들(ex. GANSpace) 보다 성능 향상 (2) entangle한 latent space를 conditional하게 살펴봄으로써 disentangle하게 조절할 수 있도록 함
- (Fig2) left가 stylegan에서 생성된 이미지, middle이 Image2StyleGAN으로 웃는 얼굴로 editing한 이미지, right가 StyleFlow의 결과
- StyleFlow는 non-linear path를 찾기 때문에 feature를 뽑은 후 disentangle하게 latent vector를 수정할 수 있다고 주장
model aritecture

CNF block: Conditional Conitinous Normalizing Flows- input latent vector $z_k$ 를 attribute variable $a^+_t$을 반영하도록 학습

Joint Reverse Encoding(JRE)
- real image에서 시작을 한다고 가정하면, encoder를 통해 이미지를 $w \in \mathbb{R}^{1 \times 512}$ vector로 projection한 후, 생성된 이미지 $I(w)$의
attribute classifier$\mathcal{A}$ 로 attribute를 추정attribute classifier: face classifier API(MS) & lighting predction DRP network)
- 이후 reverse inference로 $w, a_t$에서 $z_0$ 을 추정
Conditional Foward Editing (CFE)
- image를 projection하여 얻은 고정된 $z_0$ vector에서 시작하여 target attribute $a_t’$를 반영하는 intermediate latent vector $w’$ 를 inference
1.3 Parsing 3D Information from 2D Image Generator
1.3.1 StyleGANRender
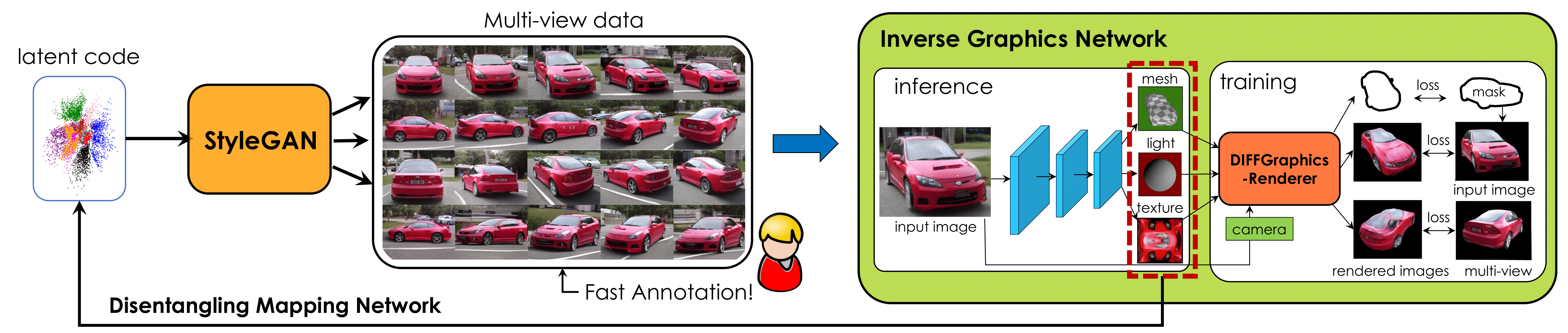
StyleGANRender: Image GANs meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering (ICLR 2021) : arxiv, project page- nvidia에서 낸 논문으로, 2D image를 바탕으로 3D image를 생성. SoTA inverse graphics network.
- StyleGAN으로 생성된 multi-view image를 토대로 Inverse Graphics Network를 학습한 후, 이 network로 latent code를 disentangle하게 구해 3D 이미지를 생성

1.4 Challenges for Supervised Approach
- How to expand the annotated dictionary size?
- How to further disentangle the relevant attributes?
- How to align latent space with image region attributes?
2. Unsupervised Approach
Identify the controllable dimensions of generator without labels/classifiers
2.1 SeFA

sefa: Closed-Form Factorization of Latent Semantics in GANs (CVPR 2021) : arxiv, project page, code

- latent vector 중 특정 feature를 변화시키는 layer가 어디인지 찾은 후 이를 조절함으로써 image를 editing
- Human-in-the-loop AI content creation

Cartoon-StyleGAN (https://github.com/happy-jihye/Cartoon-StyleGAN)
2.2 GANspace

GANSpace: Discovering Interpretable GAN Controls (NeurIPS 2020) : arxiv, codePCA(Principal Component Analysis)의 방식으로 StyleGAN의 latent space와 BigGAN의 feature space의 주요 direction을 찾음
2.3 Hessian Penalty
Hessian Penalty: A weak prior for unsupervised disentanglement (ECCV 2020) : arxiv, project page- 학습 과정에
Hessian Penalty라는 간단한 regularization term을 도입하여 생성 모델의 입력에 대한 대각선을 유도 - Hessian Matrix : $i$와 $j$라는 두 attribute가 서로 disentangle하다면 $H_{ij}$는 0일 것
- Hessian panalty in training : latent space가 disentangle해지도록 훈련과정에서 Hessian panalty를 추가 (만약 $i$와 $j$가 다른 방향이지만 서로 비슷한 attribute를 생성한다면, hessain penalty term의 값이 커질 것)
def hessian_penalty(G, z, k, epsilon):
# Input G: Function to compute the Hessian Penalty of
# Input z: Input to G that the Hessian Penalty is taken w.r.t.
# Input k: Number of Hessian directions to sample
# Input epsilon: Finite differences hyperparameter
# Output: Hessian Penalty loss
G_z = G(z)
vs = epsilon * random_rademacher(shape=[k, *z.size()])
finite_diffs = [G(z + v) - 2 * G_z + G(z - v) for v in vs]
finite_diffs = stack(finite_diffs) / (epsilon ** 2)
penalty = var(finite_diffs, dim=0).max()
return penalty
2.4 EigenGAN

EigenGAN: Layer-Wise Eigen-Learning for GANs : arxiv, code- Design inductive bias of disentanglement in the generator

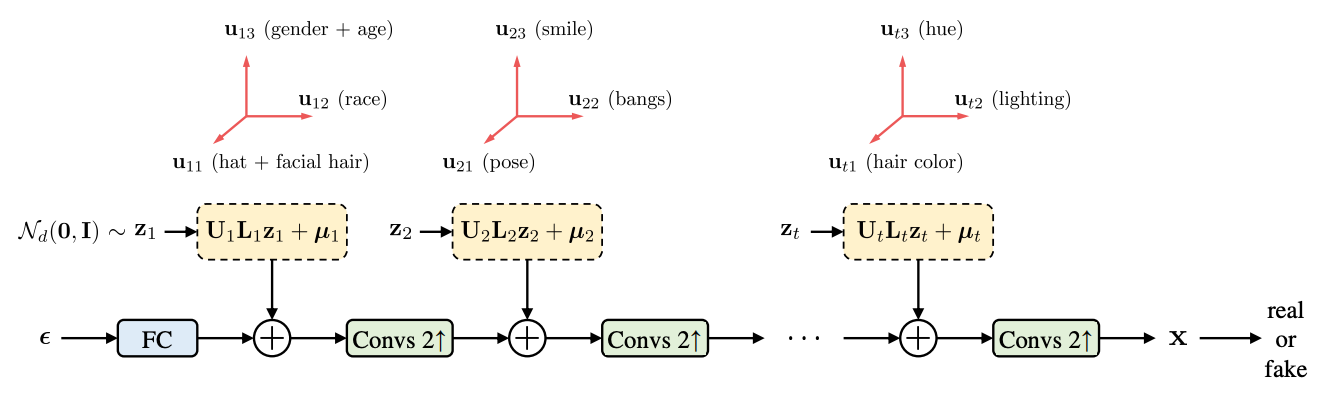
- 보통 generator는 초기에 coarse한 특징들(ex. 자세, 성별)을 학습하고, 마지막 layer로 갈수록 fine한 특징들(ex. 시선, 빛)을 학습. 이 모델은 이러한 generator의 특징을 이용하여 각 generator에 injection되는 latent vector들이 어떤 특징들을 결정하는지까지 같이 학습하겠다는 컨셉
- stylespace 이 eigengan 모델의 컨셉을 stylegan에 적용시켰다고 보면 됨
- $t$-layer의 generator와 $t$개의 latent set $z_i$를 mapping : generator의 각 layer마다 latent vector를 injection
BlockGAN,HoloGAN과 비슷
Challenges for UnSupervised Approach
- How to evaluate the results?
- How to annotate each disentangled dimensions?
- How to improve the disentanglement in GAN training?
3. Zero-Shot Approach
Align language embedding with generative representations
3.1 StyleCLIP

StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (arXiv 2021) : arxiv, review, codeStyleGAN과CLIP을 baseline으로 삼아 text기반의 이미지를 생성한 모델

세가지 방식으로 CLIP 기반의 생성모델을 제안. 자세한 architecutre 설명은 이 링크를 참고
- Latent Optimization
- Latent Mapper
- Global Direction
3.2 Paint by Word

- Paint by Word (2021) : arxiv
- brush로 특정 영역을 색칠한 후, text를 입력하면 이를 바탕으로 이미지를 수정 (CLIP model의 joint-embedding space를 사용)
3.3 DALL.E

DALLE: Zero-Shot Text-to-Image Generation (ICML 2021) : arxiv, project page, mini-dalleText-to-Image Generation: OpenAI에서 공개한 모델로, text로 부터 이미지를 생성하는 모델 (transformer 기반)- 250M(2.5억개)의 text-image pair로 학습. 12B(120억개)의 parameter
- Train a discrete variational autoencoder (
dVAE) - Train an autoregressive transformer to model the joint distribution of text and image tokens
Latent Spaces of GAN’s Generator
GAN Inversion 및 Encoder에 관한 건 아래의 글 참고

z space: stochastic한 분포에서 뽑은 random vector- StyleGAN이 나오면서 latent space들이 더 확장되었음
w space: MLP를 거쳐 얻은 vector. w vector를 AdaIN 한 후, Generator의 각 layer에 injection되었었음S space:w를 AdaIN한 후에 얻은 style vector (Layer-wise codes)w+ space: GAN inversion을 하면서 도입된 space.w vector는 모든 AdaIN에 들어가는 vector들이 같았다면,w+ vector는 다름p/p+ space

StyleSpace 가 가장 disentangle
-
StyleSpace: StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation (CVPR 2021) : arxiv, code, code2 -
GHFeat: Generative Hierarchical Features from Synthesizing Images (CVPR 2021) : arxiv, project page
Encoding Real Image into StyleGAN space

최근에는 GAN을 기반으로 생성된 이미지를 Inversion한 후 이를 manipulation하여 image를 editing하는 연구가 대세 🙃

- 이미지 reconstruction에도 StyleSpace를 이용한게 가장 성능이 좋음
ALAE: Adversarial latent autoencoders (CVPR 2020) : arxiv, codeIdInvert: In-Domain GAN Inversion for Real Image Editing (ECCV 2020) : arxiv, review, codeGHFeat: Generative Hierarchical Features from Synthesizing Images (CVPR 2021) : arxiv, project page
Applying the pretrained GAN model to image processing tasks

- GAN-Inversion을 통해 다양한 task도 가능함
댓글남기기