
[Paper Review] BDInvert: GAN Inversion for Out-of-Range Images with Geometric Transformations 논문 리뷰
업데이트:
-
Paper : GAN Inversion for Out-of-Range Images with Geometric Transformations (ICCV 2021 / Kyoungkook Kang, Seongtae Kim, Sunghyun Cho)
Base-Detail Invert (BDInvert)
🤔 결과가 굉장히 인상적인 모델이 나왔다. 올해 포스텍에서 발표한
BDInvert라는 모델인데, align이 맞지 않는 이미지들에 대해서도 inversion 및 reconstruction을 잘한다.아직 image editing 성능과 속도면에서는 한계가 있어보이지만, alignment를 강하게 걸어야하는 stylegan-based model을 align이 안된 이미지들에 대해서도 잘 생성되도록 만들었다는 점에서 아주 impressive한 모델인 것 같다.
- GAN Inversion은 in-domain에 있는 latent code를 찾는게 중요하지만, 그동안은 align이 잘된 이미지들에 대해서만
in-domain latent code를 구할 수 있었다. BDInvert에서는 이 문제점을 꼬집어 align이 안된 이미지에 대해서도 inversion을 잘할 수 있도록 만든다.- 저자들은
BDInvert가 semantic editing이 가능하도록 regularized inversion 방식을 제안하여 latent code를alternative latent space로 inversion하였다.

Real image를 editing 하려면 GAN의 pre-trained model과 align이 잘된 in-domain latent code를 찾아야한다.
- out-domain에 있는 latent code를 찾으면 image reconstruction은 잘되지만, editing 성능이 떨어질 수 있음
align이 안된 이미지를 넣으면 Fig1 처럼 이상한 이미지가 생성되며, image manipulation 역시 잘 안된다. 본 논문에서는 align이 안된 이미지(ex. translation, rotation, scaling..)에 대해서도 recon과 editing이 잘되도록 stylegan의 architecture를 발전시켰다.
Model
Alternative Latent Space $\mathcal{F} / \mathcal{W}^{+}$
out-of-range image (unaligned image)는 pre-trained GAN model의 original space로 inversion 되기 어렵다. 따라서 본 논문에서는 $\mathcal{F} / \mathcal{W}^{+}$ 라는 새로운 latent space를 제안하며 이미지를 이 space로 inversion 한다.

1. The base code space $\mathcal{F}$
- $\mathbf{w}_{M}$ 이 들어가기 전에 있는, generator의 coarse-scale feature map
StyleGAN v1에서는 특정 scale의 AdaIN layer 바로 직전에 $f$ 를 두었고,StyleGAN v2에서는 특정 scale의 conv layer 바로 직전에 $f$ 를 둠-
본 논문에서는
8x8,16x16scale에 $f$를 두어서 실험하였음 - $f$ 는 image를 wild하게 encoding ! (geometric transformation을 encoding)
- image editing이 가능하도록 다양한 local variation을 지원
- 예를 들어, $f$ 가 CNN의 feature map이라면 단순히 $f$ 를 x나 y축의 방향으로 shift함으로써 shifed된 image를 얻을 수 있음
2. The detail code space $\mathcal{W}^{+}$
-
$\mathbf{w}{M+}=\left{\mathbf{w}{M}, \cdots, \mathbf{w}_{N}\right}$ : generator의 fine scale하게 조절하기 위한 latent code
- geometric transformation과 무관. 즉 image의 translation에 invariant 함
- $\mathcal{W}_{M+}$는
StyleGAN v1, v2에서 AdaIN이나 demodulation operation으로 조절되므로 image의 translation에 invariant 함
- $\mathcal{W}_{M+}$는
- sementic manipulation이 가능하도록 지원
3. RGB Block
StyleGAN v2에서는 각 block 마다 RGB 값을 구한 후, 이를 upsample하여 다음 scale의 RGB와 더하는 방식으로 RGB feature map을 뽑음: 참고 링크- 본 논문은 아랫단의 block을 날려버리기 때문에 초기 RGB값이 없음
- 저자들은 실험 중 small-scale에서 관찰되는 feature map이 거의 0에 수렴하다는 것을 확인하였고, 그림 2(c)처럼 초기값을 0으로 둠
4. Generate Images
original image $I$
\[I=G\left(\mathbf{w}^{*}\right)=G\left(\mathbf{f}, \mathbf{w}_{M+}\right)\]transformed image $T(I)$
\[T(I) \approx G\left(T^{\prime}(\mathbf{f}), \mathbf{w}_{M+}\right)\]- $T’$ : a geometric transformation operator corresponding to $T$ whose scale is adjusted according to the relative scale of $f$ to $I$

(a) in-domain latent code $\left(\mathbf{f}, \mathbf{w}_{M+}\right)$ 를 sampling 한 다음에 StyleGAN2로 이미지를 생성
(b) $f$ 를 shift 하여 shift된 이미지를 생성
(c) manipulated latent code $\mathbf{w’}_{M+}$ 를 통해 image를 semantic하게 editing 함
(d) (b)와 (c)를 같이
Regularized Inversion to $\mathcal{F} / \mathcal{W}^{+}$
Optimization Approach
본 논문은 optimization 방식으로 latent code를 구한다. optimization 방식으로 latent code를 구하면 recon은 매우 잘되지만 sementic한 editing이 어려워지므로, encoder network를 base로 하여 추가적으로 regularization을 한다.
Encoder를 사용하기는 하지만, 이는 latent code의 정규화를 위해서 하는거지 Encoder에서 구한 initial latent code에서 출발하여 optimization을 하는 hybrid한 방식은 아니므로 latent vector를 구할 때 속도적으로는 굉장히 느리다.
Reconstruction Loss
이미지 $I$ 가 주어지면, recon loss로 latent code $\mathbf{w}^{*}$ 를 찾음
\[L_{\text {recon }}\left(\mathbf{w}^{*}\right)=L_{M S E}\left(\mathbf{w}^{*}\right)+\omega_{p e r} L_{p e r}\left(\mathbf{w}^{*}\right)\]- $L_{M S E}$ : MSE(mean-squared-error) loss
- $L_{p e r}$ : perceptual loss
- $F$ : perceptual distance를 구해주는 LPIPS network

다만 recon loss로 optimize하는 방식으로 latent code를 구하면, image recon은 잘되지만 out-domain으로 inversion되어 editing이 잘 안된다. (Fig 4(f) 참고)
따라서 본 저자들은 $\mathbf{f}, \mathbf{w}_{M+}$ 를 regularization 하는 방식을 통해 이 문제를 해결하고자 하였다.
Regularization on Detail Code $\mathbf{w}_{M+}$
본 논문에서는 $\mathbf{w}_{M+}$ 를 in-domain space로 보내기 위해 다음 논문에서 제시된 $\mathcal{P}-\text { norm }^{+}$ space-based regularization 방식을 사용하였다
Regularization on Base Code $\mathbf{f}$
Fig 4(g)를 보면, $\mathbf{w}_{M+}$의 regularization 만으로 문제가 해결되지 않는다. 따라서 본 논문에서는 $\mathbf{f}$ 역시 정규화를 시켰다.
$\mathbf{f}$ 는 regularization을 위해 encoder에서 구한 initial latent code $\mathbf{f}^{o}$ 와 값이 비슷하도록 regularization loss $L_{\mathbf{f}}\left(\mathbf{w}^{*}\right)$ 로 제약을 준다.
\[L_{\mathbf{f}}\left(\mathbf{w}^{*}\right)=\left\|\mathbf{f}^{o}-\mathbf{f}\right\|^{2}\] \[L\left(\mathbf{w}^{*}\right)=L_{r e c o n}\left(\mathbf{w}^{*}\right)+\omega_{\mathbf{f}} L_{\mathbf{f}}\left(\mathbf{w}^{*}\right)\]Encoder for Base Code $\mathbf{f}$
Encoder는 initial base code $\mathbf{f}^{o}$ 를 추정하는게 목표이다. $\mathbf{f}^{o}$는 8x8이나 16x16과 같은 small-spatial resolution을 가지므로 encoder는 학습할 때 original resolution의 이미지를 input으로 사용하지 않으며(down-scaling된 걸 사용), network 자체도 기존에 비해 가볍다.
Encoder는 VGG network와 비슷하게 11개의 conv block과 3개의 pooling layer로 구성된다.
Training
- random으로 latent code $z$를 생성한 후, $z$로부터 $\left(\mathbf{f}^{g t}, \mathbf{w}_{M+}^{g t}\right)$ 와 생성된 이미지 $I$ 를 구함
- 이미지 $I$를 downscaling 한 이미지가 $I_{\downarrow}$
- loss function에서 첫번째가 mse loss, 두번째가 perceptual loss
🧐 base code에 대한 ground trouth $\mathbf{f}^{g t}$를 알고 있는데, 왜 다음과 같은 Loss functiond으로 encoder를 학습했을까?
저자들은 직접 실험해본 결과 $\left|E\left(I_{\downarrow}\right)-\mathbf{f}^{g t}\right|^{2}$ 와 같이 $\mathbf{f}^{g t}$ 값을 기준으로 encoder를 학습시키면 오히려 recon 성능이 떨어진다고 보고한다.
또, 저자들은 이 encoder가 기하학적으로 변형된 이미지들에 대해서도 잘 encoding한다고 보고한다. 이는 CNN 자체가 spatially-invariant한 특성을 갖고 있기 때문이다.
Experiments
- FFHQ 데이터셋으로 학습된 pretrained model과 CelebA-HQ에서 random으로 뽑은 이미지를 사용
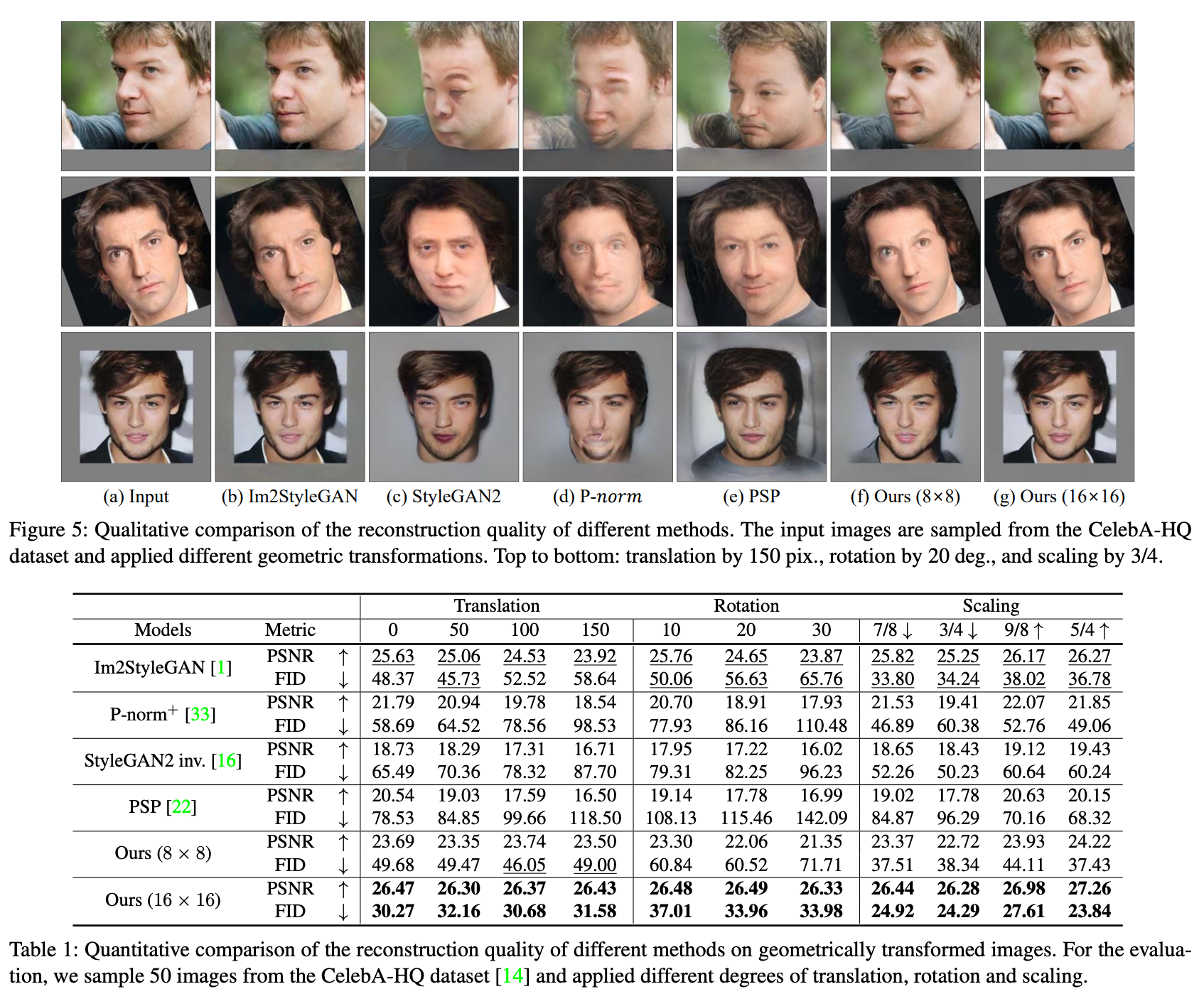

Recon 뿐만 아니라 sementic한 editing도 잘됨

- base code $f$ 로는
8x8,16x16을 사용 8x8를 사용했을 때가 sementic한 editing이 더 잘된다고 보고
마치며..
굉장히 흥미롭게 본 논문이다 ! github에 코드가 공개되어있던데,, 한번 실험해보고 성능이 어떤지 직접 확인해봐야겠다 😊
댓글남기기