
[Paper Review] PGGAN : Progressive Growing of GANs for Improved Quality, Stability, and Variation 논문 분석
업데이트:
✍🏻 이번 포스팅에서는 layer를 점진적으로 쌓아 고해상도의 이미지를 생성한 NVIDIA의 PGGAN(Progressive Growing of GANs) model에 대해 살펴본다.
-
Paper : Progressive Growing of GANs for Improved Quality, Stability, and Variation (2018 / Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen)
1. Introduction
Autoregressive models(ex. PixelCNN), VAEs, GANs 등 많은 생성모델들이 있다. 본 논문은 이 중에서도 GAN의 architecture를 사용한 논문이다.
- Autoregressive models : sharp images, slow to evaluate, no latent space
- VAE : fast to train, blurry images,
- GANs : sharp images, low resolutioin, limited variation, unstabble training
GAN
GAN의 generator는 latent code로부터 이미지를 생성하며, 이상적인 경우에는 이 이미지의 분포를 training distribution와 구별하기 어렵다. discriminator는 이미지를 잘 평가하도록 학습한다.
보통 GAN에서는 generator를 잘 학습시키는 것이 중요하다.(discriminator는 학습중에만 사용되고 이후에는 버려짐)
- GAN에 대한 설명은 이 글을 참고 : [Paper Review] Generative Adversarial Networks(GAN) 논문 설명 및 pytorch 코드 구현
⭐ Challenge
GAN에는 해결해야할 문제점들이 있다.
1. generated distribution과 training distribution들이 겹치는 부분(overlap)이 적다면, 이 분포들간의 거리를 측정할 때 gradient는 random한 방향을 가리킬 수 있다.
- original GAN(이안 굿 팰로우)에서는 Jensen-Shannon Divergence를 distance metric으로 사용했다면, 최근에는 least squares나 Wasserstein distance등의 metric을 사용해서 모델을 안정화 시켰다.
2. mode collapse : generated distribution이 실제 데이터의 분포를 모두 커버하지 못하고 다양성을 잃어버리는 현상을 뜻한다. G는 그저 loss만을 줄이려고 학습을 하기 때문에 전체 데이터 분포를 찾지 못하게 되고, 결국에는 하나의 mode에만 강하게 몰리게 되는 경우이다.
- 예를 들어, MNIST에서
G가 특정 숫자만을 생성하게되는 경우가 이에 속한다.
3. High-resolution의 image를 생성할 수록, 가짜 이미지라고 판별하기 쉬워진다.
4. High-resolution의 이미지를 만들기 위해서는 memory constraint 때문에 더 작은 minibatch를 사용해야하고, training stability 역시 떨어진다.
⭐ 따라서 이러한 문제점들을 해결하기 위해 PGGAN에서는 Generator와 Discriminator를 점진적으로 학습시킨다. 즉, 만들기 쉬운 low-resolution부터 시작하여 새로운 layer를 조금씩 추가하고 higher-resolution의 detail들을 생성한다.
2. Progressive Growing of GANs

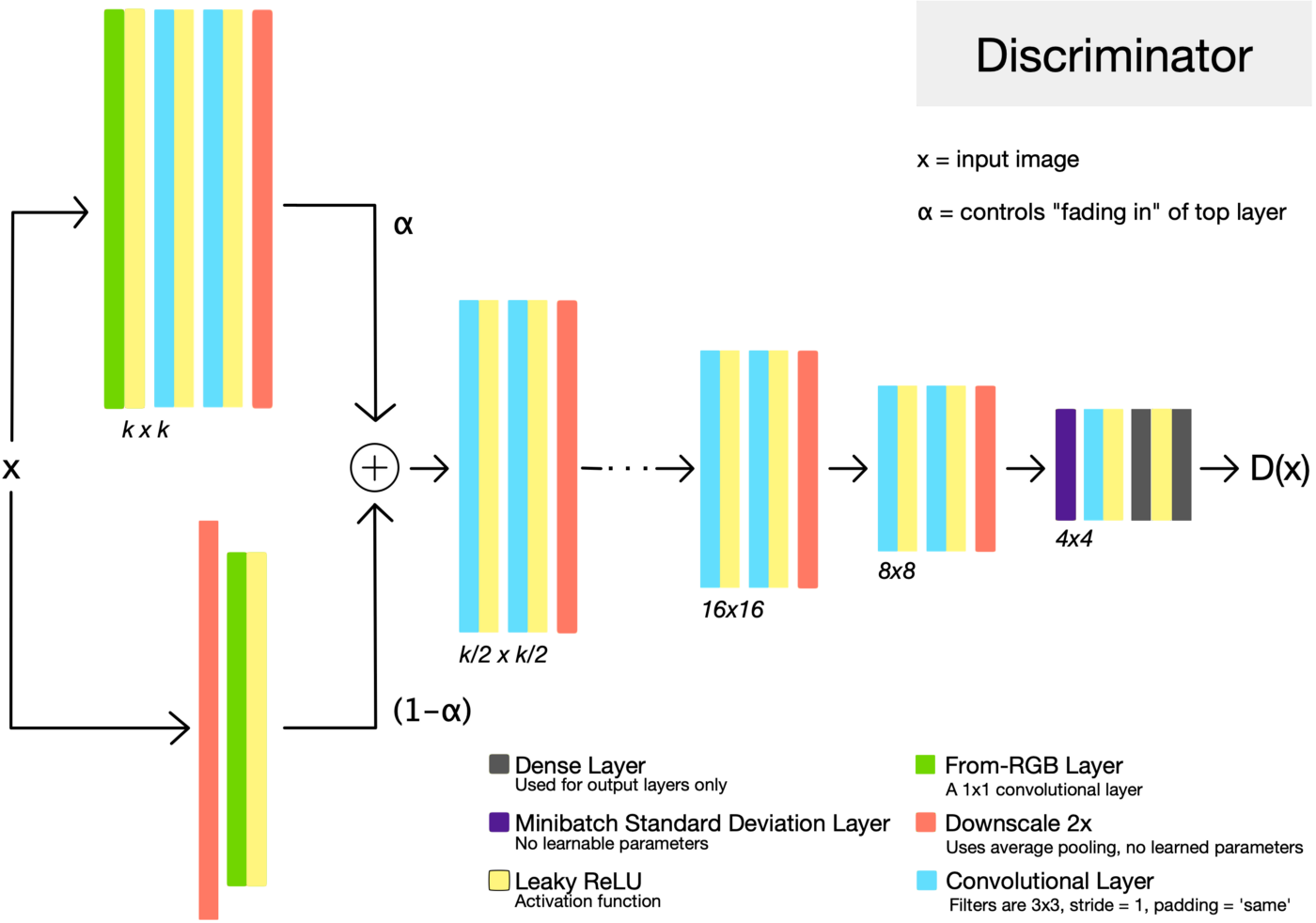
위의 그림처럼 PGGAN은 low-resolution의 image에서 시작하여 점차 layer를 추가하면서 high-resolution을 학습하게 된다. 또한, discriminator는 generator와 대칭의 형태를 이루고 있으며 모든 layer들을 학습할 수 있다.
처음에는 large scale(low frequency)의 정보들을 학습하고, 점차 fine scale(higher frequency)의 정보들을 학습하게 된다.

이러한 Progressive training은 몇가지 장점이 있다.
- Stable : low-resolution의 이미지를 학습하면 class information도 적고 mode도 몇없기 때문에 안정적이다.
- 관련 연구 : WGAN-GP loss, LSGAN loss
- Reduced training time : PGGAN은 lower resolution에서부터 비교하여 학습을 하기 때문에 학습속도가 2-6배나 빨라진다.
Fading in higher resolution layers

G와 D의 resolution을 upsampling할 때, PGGAN은 새로운 layer에 fade in하는 방식을 사용한다.
(a) stabilize
- (16x16x512) ->
to RGB-> (16x16x1) ->from RGB-> (16x16x512)
(b) transition (fade in) : 해상도를 늘리는 과정
- 이 그림의
to RGB는 32x32에 최적화된 1x1 convolution - 이때 $\alpha$값이 핵심이다. 처음에는 $\alpha$를 0으로 초기화시켜주고(16x16을 2x로 upsampling하고
to RGB를 거쳐 오도록), 점점 $\alpha$를 1로 증가시켜가며 학습을 해서 32x32에 대해 생성한 값을 불러오도록 한다.
(c) stablilize
resolution을 높이면서(32x32) 학습을 진행할 때, 기존에 학습했던 이미지에 대한 정보(16x16)을 잊어버릴 수도 있으니까 residual block을 이용하여 한번 더 더해주는 것이다. 해상도를 줄이는 경우도 마찬가지의 이유로 Fade in을 해준다.
😉 사실 이 technique은 stylegan2로 가면서 거의 사용하지 않아서.. 그냥 이런게 있었다 정도만 알면 될 것 같다.
- 여러개의 생성자나 판별자들을 사용하는 연구들이 있었음
- PGGAN은 이에 motivate되어 latent에서부터 여러 단계에 걸쳐 high-resolution의 image로 mapping하는 network를 만들었음. 다만 다른 점은 PGGAN은 Single GAN !!
3. Increasing Variation using Minibatch Standard Deviation
Goal : Encouraging the minibatches of generated and training images to show similar statics
PGGAN에서는 mode collapsing을 해결하기 위한 한가지 방법인 Mini-batch discrimination의 방식을 사용한다. mini-batch 별로 생성이미지와 실제 이미지 사이의 거리 합의 차이를 목적함수에 추가하는 것이다.
- 이 값을 discriminator의 어디에나 추가해도 되지만, 보통은 맨 뒤에 추가하곤 한다.
- 이 방식 외에도 repelling regularizer을 사용할 수도 있다.
4. Normalization in Generator and Discriminator
GAN에서는 G와 D가 경쟁을 할 때 signal magnitude가 커지기 쉽다. 따라서 보통은 batch normalization을 하곤 한다. 그런데 PGGAN에서는 signal magnitude을 할 때 이러한 현상이 나타나지 않기 때문에 parameter를 학습시키기 위한 방식으로 다른 접근 방식을 사용한다.
4.1 Equalized Learning Rate
batch size가 큰 일반 GAN의 경우 batch norm을 사용해도 문제가 없지만, PGGAN에서는 high-resolution의 이미지를 생성해야하기 때문에 작은 사이즈의 batch를 사용하게 되고 그렇기 때문에 initilization이 굉장히 중요해진다.
본 논문에서는 모든 layer의 learning speed가 같도록 equalized learning rate의 방식을 사용한다. gradient의 학습 속도가 parameter와 무관하도록 standard deviation으로 gradient를 normalize하는 방식이다. (weight를 $N(0,1)$의 정규 분포에서 initialization 한 후, runtime시에 scaling 해준다.)
(참고) Xavier initilization 와 He initilization
- Xavier initilization


- 만약에 variation이 1보다 크다면 network를 deep하게 쌓을 수록 variance가 커져서 exploding이 되고, variation이 1보다 작다면 vanishing이 된다.
- 따라서 이러한 현상을 막기 위해서 forward activation이나 gradient에서 input activation $x_i$의 평균이 0, variation이 1이면 output activation $Y$의 평균과 분산도 각각 0, 1로 만들어줘야 한다.
- $Var(Y)=1$이 되려면 $nVar(W)=1$이 되어야함으로 $Var(W)$은 $\frac{1}{n}$이 되어야한다.
⭐ $W \sim N(0, \frac{1}{n})$이 되도록 학습을 하면 network를 deep하게 쌓아도 layer마다 standard variation이 1이 될 것이다.
- Xavier initilization은 input에서의 activation이 linear라고 가정을 하지만, He initilization은 이를 ReLU나 Leaky-ReLU로 가정을 한다.
- ReLU와 같은 activation function을 사용하면 input의 절반은 0이 되기 때문에 Variation이 1이 된다는 가정이 틀릴 수도 있다. 따라서 He’s initilization에서는 이를 보정해주는 과정이 필요하다.
-
Equalized Learning Rate

사실 forward 계산에서는 Equalized LR과 He initialization는 정확하게 동일하다.(순서만 다름)
차이는 gradient를 update할 때 생긴다. He initialization를 쓴다면 RMSProp이나 Adam과 같은 adpative stochastic gradient descent을 쓸 때 network의 파라미터가 scale에 independent하게 update가 되게 된다.
4.2 Pixelwise Feature Vector Normalization in Generator
D와 G가 경쟁을 하면서 크기가 control이 잘 안되는 경우를 대비하여 PGGAN에서는 convolutional layer후 generator에서 각 pixel 별로 normalization을 해줬다.
\[b_{x, y}=a_{x, y} / \sqrt{\frac{1}{N} \sum_{j=0}^{N-1}\left(a_{x, y}^{j}\right)^{2}+\epsilon}\]😉 이 technique 역시 stylegan2부터는 잘 사용하지 않는다.
5. Experiments


다른 GAN들과 비교했을 때 고해상도의 이미지가 잘 출력된다.

또한, 학습 속도 역시 매우 빠르다.
6. Discussion
이전의 GAN들에 비해 PGGAN은 high-resolution에서도 안정적으로 학습을 할 수 있었다. 다만, 아직 현실적인 사진을 만들기에는 한계가 있다.
–
7. Code

8. Opinion
stylegan1의 baseline이 되는 PGGAN 논문을 읽었다. 모델의 architecture자체는 어렵지 않지만, 세부적인 technique들이 이해하기 어려웠던 논문이었다.
Reference
- https://hackmd.io/@_XGVS6ZYTL2p6MEHmqMvsA/HJ1BBDtP4?type=view
- https://github.com/deepsound-project/pggan-pytorch
- Naver AI LAB 최윤제 연구원님 발표자료
댓글남기기