
[Paper Review] StyleGAN2 : Analyzing and Improving the Image Quality of StyleGAN 논문 분석
업데이트:
✍🏻 이번 포스팅에서는 기존의 stylegan을 발전시킨 nvidia research의 StyleGAN2에 대해 살펴본다.
-
Paper : Analyzing and Improving the Image Quality of StyleGAN (2020 / Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila)
본 논문은 기존의 SoTA였던 StyleGAN의 architecture를 발전시켜 새로운 SoTA의 결과를 낸 논문으로, 현재 연구되고 있는 많은 생성모델들은 stylegan v2를 baseline으로 하고 있다.
1. Introduction
기존의 styleGAN은 input latent code $\mathbf{z} \in \mathcal{Z}$ 대신, mapping network $f$를 도입하였다.(intermediate latent code $\mathbf{w} \in \mathcal{W}$ ) 또한, Affine transform을 사용하여 style을 생성했으며 stochastic variation을 주기 위해 noise를 사용했다.
Problem
이미지의 feature map에서 계속해서 정체불명의 물방울이 생김
⭐ StyleGAN2는 G의 normalization을 다시 디자인 하여 물방울을 제거하고, Progressive Growing이 아닌 다른 training 방식을 사용하여 고해상도의 이미지를 생성하였다.
2. Removing normalization artifacts

StyleGAN에서 생성된 이미지들은 물방울과 같은 blob-shaped artifacts 들이 생겼었다. (그림1) 이 현상은 모든 feature map에서 나타나며, 고 해상도의 이미지일수록 강하게 나타난다.
2.1 Generator architecture revisited

기존의 StyleGAN v1은 style block 내에서 bias와 noise을 적용했었는데, 이 때문에 style이 오히려 현재 style의 크기에 반비례하게 적용되었다. stylegan2에서는 bias & noise를 styleblock 외부로 옮겨주어 이를 해결하였다.
- Instance Normalization : AdaIN을 없애고 feature map마다 평균과 표준편차를 계산
AdaIN을 없애는 이유: blob-shaped artifacts이 왜 생기는지에 대한 명확한 원인은 못찾았지만, 이는 AdaIN 때문에 생기는 것으로 추측된다. (stylegan에서 normalization를 없애니 물방울이 생기는 현상들이 사라지는 것을 발견) 따라서 v2에서는 이를 제거하였다.
- modulation을 통해 scaling & biasing

- Blue block : noise를 더해주는 부분과 bias를 더해주는 부분을 normalization이후로 옮김
- why? : noise는 보통 gaussian 정규분포에서 뽑는데, conv layer이후에 이 값을 더해주면 noise의 값이 비교적 작으므로 이 영향이 반영되지 않을 수도 있다. 따라서 conv layer의 결과값을 normalize해준 후에 이 noise를 더해주었다.
- Red block : 실험을 해보니 평균(mean)을 구하지 않고 표준편차(standard deviation)만을 사용하여도 normalization과 modulation을 할 수 있음을 확인하였다.
- normalize를 해줄 때 mean값을 빼주는 과정을 안해줘도 됨
- Green block : 초기의 Learned constant input에서 bias, noise, normalization을 해주지 않아도 별다른 성능 저하가 나타나지 않아서 이들도 제거해주었다.
2.2 Instance normalization revisited

- Revised architecture(c)는 modulation, convolution, normalization으로 구성되어있다.

- StyleGAN2의 최종 모델인 (d)에서는 각 feature map에서 modulation(scaling)을 하는 대신, convolutional weight에 modulation을 해주었다.
-
weight를 modulation하는게 feature를 modulation하는 것보다 학습속도가 빠름 \(w_{i j k}^{\prime}=s_{i} \cdot w_{i j k}\)
-
original weight $w_{i j k}$에 scaling $s_i$을 해줌 → modulated weight $w_{i j k}^{\prime}$
-
-
instance normalization은 output feature map이 scaling되지 않도록 정규화를 하는 과정이다.(Variance를 1로 만드는 과정) stylegan2에서는 weight에 scaling을 하므로 conv 연산 후에도 scaling이 되어있지 않도록 convolution layer의 weight를 조정해주었다.
-
⭐ (가정) : input feature map의 표준편차(standard deviation)는 1, i.i.d random variables
-
modulation과 convolution 후에 표준편차는 $\sigma_{j}=\sqrt{\sum_{i, k} w_{i j k}^{\prime} 2}$
-
따라서 output feature map의 분산도 1이 되도록 다시 scaling을 해줌 : Demodulation $w_{i j k}^{\prime \prime}=w_{i j k}^{\prime} / \sqrt{\sum_{i, k} w_{i j k}^{\prime}2+\epsilon}$
-
instance normalization은 항상 variance를 1로 만들어준다는 장점이 있지만, blob-like artifact를 만들곤 한다. 따라서 stylegan2에서는 IN 대신 Weight Demodulation이라는 정규화 방식을 사용하였다.(WD는 특정 가정에서만 성립되는 약한 정규화)

생성 이미지에 물방울이 생기는 현상들이 사라졌다. (FID도 거의 그대로)
3. Image quality and generator smoothness

FID나 P&R(Precision and Recall)이 같더라도 PPL이 낮은 사진이 질이 더 좋다.

PPL(Perceptual Path Length)이 낮을 수록 high-quality image를 만든다.

stylegan1에 비해 stylegan2의 PPL이 작다😊
3.1 Lazy regularization
StyleGAN은 non-saturated adversarial loss인 BCE loss와 R1 regularization을 사용한다.
보통 BCE loss와 R1 regularization의 조합을 많이 사용 ✔
다만 stylegan v1은 R1 reg를 매 iteration마다 해줬다면, stylegan v2에서는 computation cost를 줄이기 위해 R1 reg를 매번 해주지는 않는다. (ex. 16 iteration에 한번)
따라서 Lazy regularization이라고 부른다.
\[R_{1}(\psi)=\frac{\gamma}{2} E_{p_{D}(x)}\left[\left\|\nabla D_{\psi}(x)\right\|^{2}\right]\]3.2 Path Length Regularization
\[\mathbb{E}_{\mathbf{w}, \mathbf{y} \sim \mathcal{N}(0, \mathbf{I})}\left(\left\|\mathbf{J}_{\mathbf{w}}^{T} \mathbf{y}\right\|_{2}-a\right)^{2}\]- PPL regularization을 빼도 stylegan2이 어느정도 잘 동작함.
- 자세한 설명은 생략
4. Progressive growing revisited
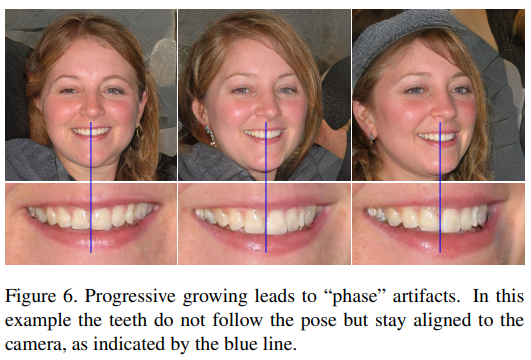
PGGAN은 고해상도의 이미지를 잘 생성하지만, Phase artifacts(strong location)문제 가 있다.
- Phase artifacts(strong location): 눈동자나 이빨의 모양은 잘 생성이 되지만, 자세를 바꿔도 위치가 고정(Figure 6)
PGGAN의 architecture를 따르는 stylegan 역시 동일한 문제가 생겨 stylegan v2에서는 이를 해결하고자 progressive growing의 학습방식을 채택하지 않았다.
4.1 Alternative network architectures
- progressive growing의 방식을 따르지 않고도 high-quality의 이미지를 잘 생성할 수 있도록 styleGAN을 변형

본 논문은 세가지의 Generator와 Discriminator의 architecture에 대해 실험을 했으며, 이 중 skip generator와 residual discriminator의 방식으로 architecture를 구성하였다.
4.2 Resolution usage
Progresive Growing에서는 Generator가 low-resolution feature에 집중을 하다가 서서히 finer detail을 잡아가는 방식으로 학습을 한다면, 위의 StyleGAN에서는 G가 low-resolution의 이미지를 생성하다 점차 high-resolution의 이미지를 생성하는 방식으로 학습을 한다.

(b)는 (a)보다 channel의 수를 늘린 경우이다.
기존의 setting (a)에서는 고 해상도(1024)에서 filter의 영향력이 작아 variance가 작았다면, channel size를 늘렸을 때에는 generator가 high-resolution의 이미지를 생성할 수 있게 되었다.
5. Projection of images to latent space

다음은 생성된 이미지를 latent space로 projection한 후에, 그 latent space를 이용해 다시금 이미지를 생성한 결과이다.
- random init
z에서 이미지를 생성한 후, target 이미지와 가장 비슷한 이미지의 latent space를 찾는 방식으로 projection을 함.
StyleGAN v1은 자기 자신이 생성한 이미지에 대해서도 projection을 잘 못하지만,StyleGAN v2는 자신이 생성한 이미지에 대해서는 latent space로 projection을 잘 시킨다.

LPIPS distance를 계산해보면, StyleGAN은 real와 생성 이미지를 잘 구별 못하지만 StyleGAN2는 구별을 잘 한다.
6. Conclusions

위에서 제시한 styleGAN2의 기법을 사용하면 성능이 좋아진다.

StyleGAN2는 StyleGAN의 architecture를 개선하여 blob-shaped artifacts문제를 해결하고 high-quality의 이미지를 생성하였다.
댓글남기기