
[Paper Review] An Image is Worth 16X16 Words: Transformers for Image Recognition at Scale 논문 분석
업데이트:
이번 포스팅에서는 NLP의 Transformer model을 컴퓨터 비전 분야에 적용한 Vision Transformer (ViT) 논문을 리뷰할 예정이다. 논문에서는 ViT를 SoTA인 CNN 모델과과 비교했을 때 훌륭한 결과를 냈다고 주장한다.
주요 task는 image classification이며 pre-trained 된 large-scale의 data를 사용하였다.
- Paper : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020 / Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby)
1. Introduction
Transformer model(Vaswani et al, 2017)은 NMT(Neural Machine Translation)을 위해 제안되었으며, 아직까지도 NLP 분야에서 지배적이다. Transformer는 연산이 효율적이고, 확장성이 좋기 때문에 아주 큰 data의 학습을 가능하게 했고(100B의 parameter), 현재 SoTA인 BERT, GPT 등의 architecture들은 모두 transformer를 발전시켜 아주 좋은 성능의 모델을 만들었다.
NLP분야에서 attention이 두각을 나타내자, computer vision에도 이를 적용하자는 움직임이 나타났다.
- combing CNN-like architectures with self-attention : Non-local neural networks(2018), End-to-end object detection with transformers(2020)
- replacing the convolutions entirely : Stand-Alone Self-Attention in Vision Models(2019), Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation(2020)
이와 같이 다양한 연구들이 있었으나, attention pattern이 특이하여 hardware accelerator를 통해 효율적으로 scaling하기가 쉽지 않다는 단점이 있었고, 계속해서 large-scale image recognition분야에서는 ResNet이 SoTA로 사용되었다.
본 논문에서는 NLP의 transformer의 확장성을 컴퓨터 비전에 적용하기 위해 Transformer architecture를 최소한만 수정하여 이미지를 처리하도록 한다. (image를 patch단위로 split한 후 이를 선형변환 하여 Transformer의 input으로 넣는 방식을 사용한다.)
모델은 ImageNet과 같은 중간 사이즈의 dataset에서는 잘 동작하지 않으며, 이 경우에는 ResNet과 같은 기존의 vision model들이 더 좋은 성능을 낸다. 다만, ImageNet-21k dataset이나 JFT-300M dataset과 같은 large-scale의 data에 대해서는 기존의 모델들보다 더 좋은 정확도를 보였고 SoTA의 결과를 냈다.
2. Related Work
Deep learning model에서 수많은 데이터들을 전부 다 학습하는 것은 어렵다. 따라서 대부분의 Large Transformer-based model은 Transfer Learning 의 방식을 사용한다. 이는 large text corpus에서 미리 학습된 모델(pretrained model)의 일부를 수정하는 fine tuning 방식이다.
실제로 BERT 에서는 denoising self-supervised pre-training task를 사용했고, GPT에서는 language modeling의 방식으로 pre-training을 했다.
-
Transfer Learning (출처 : simonjisu/FARM_tutorial
1. Pretrained Language Modeling
-
대량의 텍스트 데이터를 이용해 비지도학습(unsupervised learning)으로 언어 모델링은 진행한다. 언어 모델링이란 인간의 언어를 컴퓨터로 모델링하는 과정이다. 쉽게 말하면, 모델에게 단어들을 입력했을 때, 제일 말이 되는 단어(토큰)을 뱉어내게 하는 것이다.
-
과거에는 단어(토큰)의 순서가 중요했었다. 즉, 일정 단어들의 시퀀스 $x_{1:t-1}$ 가 주어지면, $t$번째 단어인 $x_t$ 를 잘 학습시키는 것이었다. 이를 Auto Regressive Modeling이라고도 한다.
-
그러나, Masked Language Modeling 방법이 등장했는데, 이는 랜덤으로 맞춰야할 단어를 가린 다음에 가려진 단어 $x_{mask}$가 포함된 시퀀스 $x_{1:t}$ 를 모델에게 입력하여 맞추는 학습 방법이다. 이러한 방법이 좋은 성과를 거두면서, 최근에는 모든 언어모델링 기법들이 MLM을 기반으로 하고 있다.
2. Fine-tuning
PLM(Pretrained Language Model)을 만들고 나면, 각기 다른 downstream task에 따라서 fine-tuning을 하게 된다. Downstream task은 구체적으로 풀고 싶은 문제를 말하며, 주로 다음과 같은 문제들이다.
- 텍스트 분류 Text Classification - 예시: 영화 댓글 긍정/부정 분류하기
- 개체명인식 NER(Named Entity Recognition) - 예시: 특정 기관명, 인명 및 시간 날짜 등 토큰에 알맞는 태그로 분류하기
-
질의응답 Question and Answering - 예시: 특정 지문과 질의(query)가 주어지면 대답하기
- https://jeinalog.tistory.com/13 도 참고
-
Self-attention을 image에 적용하려면 각 pixel이 다른 모든 pixel에 attend할 수 있어야 한다. 다만, 이를 위해서는 quadratic cost가 들며, 실제 image size로 scaling되지도 않는다.
이 문제를 해결하기 위한 다양한 논문들도 있다.
- Image Transfer(2018)은 self-attention시에 query pixel이 global하게 attend를 하지 않고, local neighborhood에게만 attend를 하도록 수정했다.
- Stand-Alone Self-Attention in Vision Models(2019), On the relationship between selfattention and convolutional layers(2020) 은 convolution을 대신하여 local multi-head dot-product self attention을 사용했다.
- Sparse Transformer(2019) 이미지에 global self-attention을 할 수 있게 하는 scalable approximation 방식을 고안했다.
- scale attention의 대안으로 Axial attention in multidimensional transformers(2019) 은 다양한 size의 block을 사용하였고, Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation(2020) 는 다양한 축을 사용하여 self-attention을 효율적으로 만들었다.
위의 논문들에서 소개된 specialized attention architecture를 사용하면 computer vision task를 더 잘할 수 있지만, 이를 계산하기 위해서는 복잡한 HW accelerator가 필요하다.
CNN과 self-attention을 합치려는 시도도 많다.
- Attention augmented convolutional networks(2019)
- object detection : End-to-end object detection with transformers(2020)
- video processing : Videobert: A joint model for video and language representation learning
- image classification : Visual transformers: Token-based image representation and processing for computer vision
이 논문에서는 full-sized image에 대해 global self-attention을 적용하지 않고, 가장 최근의 연구인 iGPT처럼 image resolution과 color space를 줄인 후 image pixel에 Transformer모델을 적용한다. iGPT model은 unsupervised 방식을 사용해 이미지를 생성했으며, 이후 fine-tuning 이나 linear로 근사하는 방식을 써서 ImageNet에서의 정확도를 72%까지 만들었다.
3. Architecture
3.1 Vision Transformer (ViT)
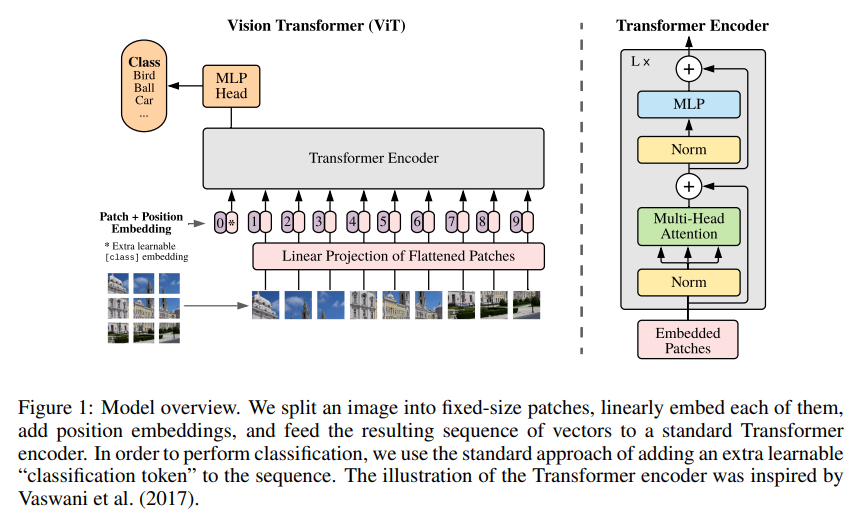
본 논문은 논문 제목에서부터 scalability를 강조한다. 따라서 ViT 모델에서는 original Transformer을 최소한만 수정하여 큰 dataset에서 학습할 때에도 효율적인 implementation이 가능하도록 하였다.
🤔 적당한 사이즈의 데이터셋에 대해서는 성능이 잘 안나와서 scalability를 강조하는 것 같기도,,
모델은 위와 같이 생겼고, transformer에서의 encoder architecture만을 차용한다.
또한, 그동안의 transformer에서는 1D의 sequence만을 다뤘다면 ViT는 2-dimension 의 image를 input으로 받는다. 따라서 이를 위해 H x W x C로 이루어진 $\mathbf{x}\in \mathbb{ R }^{ H\times W\times C }$의 이미지를 flatten된 2D patches $x_{p}\in \mathbb{R}^{N \times (P^{2}\cdot C)}$로 변환한다.
- $(P,P)$는 image patch의 resolution이며, $N=HW/P^2$의 관계를 만족한다.
Patch Embedding
-
기존의 Transformer는 모든 layer에서 $D_{model}$의 constant latent vector를 사용했다. 우리는 이러한 방식을 ViT에서도 사용하기 위해 아래의 식을 사용하여 2D의 flatten padding을
\[\mathbf{z}_{0}=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{p o s}, \quad \mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{p o s} \in \mathbb{R}^{(N+1) \times D}\]D-dimension의 linear projection에 투영하였다.- $x_p$와 embedding vector $E$ 를 내적하면 : $x_{p}\mathbf{E}\in \mathbb{R}^{N \times D}$
-
BERT의 CLS token?
Position embedding
- 위치 정보를 주기 위해 patch embedding에 positional embedding값을 더해준다.
-
본 논문에서는 2-D의 positional embedding을 사용했을 때와 학습가능한 1-D positional embedding을 사용했을 때의 성능이 비슷하여 standard learnable 1-D position embedding 을 사용한다고 한다.
-
Appendix D.3
실험에서는 4가지의 positional embedding 방식을 비교했다.
-
No positional information : input이 bag of patche와 같다
-
1-D positional embedding
-
2-D positional embedding
-
Relative positional embedding : 1-dimensional Relative Attention을 사용하여 patch들 간에 상대적인 거리를 측정하였다.
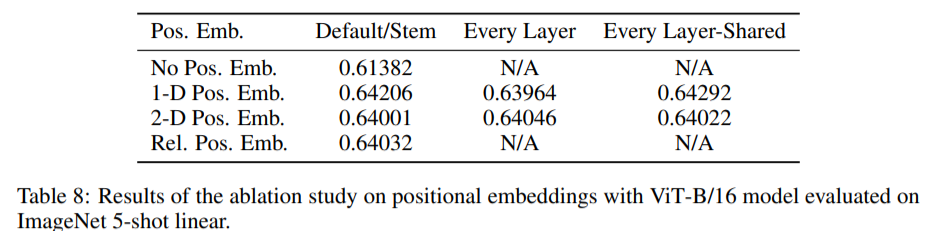
1-D와2-D의 positional embedding을 토대로 3가지의 실험을 진행했다.(1) Default : input의 오른쪽에 positional embedding을 추가
(2) Every layer : 각 layer의 시작부분에서 input과 positional embedding을 더하고 학습시키기
(3) Every layer-Shared : 학습된 positional embedding을 각 layer의 시작부에 추가해주기
실험 결과를 종합해보면, Pos Emb을 안한 경우와 한 경우의 차이는 두드러졌다. 다만, 몇차원의 Pos Emb을 했냐는 중요하지 않았다.
ViT가
pixel-level이 아니라patch-level단위로 학습을 하기 때문에 spatial information을 얼마나 encoding하는지는 중요하지 않다. patch-level의 input은 original pixel-level인224 x 224dimension와 비교하면 매우 작은 spatial dimensions을 사용한다. (ex.14 x 14) 따라서 이 작은 해상도의 positional embedding을 학습하기 위해서 2-D와 같은 고차원을 사용할 필요는 없다.
-
ViT Block
Transformer의 encoder는 모든 block마다 Residual connection과 Layernorm(LN)을 적용하였다. 따라서 이를 식으로 나타내면 다음과 같은 Multi-Layer Perceptron(MLP)가 된다.
MLP는 2개의 GELU(Gaussain Error Linear Unit) non-linearity layer를 포함하고 있다고 한다.
\[\begin{aligned}\mathbf{z}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\ell-1}\right)\right)+\mathbf{z}_{\ell-1}, & & \ell=1 \ldots L \\\mathbf{z}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{z}_{\ell}^{\prime}\right)\right)+\mathbf{z}_{\ell}^{\prime}, & \ell &=1 \ldots L \\\mathbf{y} &=\operatorname{LN}\left(\mathbf{z}_{L}^{0}\right) & &\end{aligned}\]-
MSA (Multi-Head Self-Attention)
다음은 transformer의 Self-Attention(이하 SA)식이다. $$ \begin{aligned}&[\mathbf{q}, \mathbf{k}, \mathbf{v}]=\mathbf{z} \mathbf{U}_{q k v}\ \quad\quad \mathbf{z} \in \mathbb{R}^{N \times D}\quad \mathbf{U}_{q k v} \in \mathbb{R}^{D \times 3 D_{h}}\end{aligned}$$ $$A=\operatorname{softmax}\left(\mathbf{q k}^{\top} / \sqrt{D_{h}}\right) \quad A \in \mathbb{R}^{N \times N}$$ $$\operatorname{SA}(\mathbf{z})=A \mathbf{v}$$ self-attention을 k개의 head로 나눠 계산하는 게 MSA이다. $$\operatorname{MSA}(\mathbf{z})=\left[\mathrm{SA}_{1}(z) ; \mathrm{SA}_{2}(z) ; \cdots ; \mathrm{SA}_{k}(z)\right] \mathbf{U}_{m s a} \quad \mathbf{U}_{m s a} \in \mathbb{R}^{k \cdot D_{h} \times D}$$
Hybrid Architecture
\[\mathbf{z}_{0}=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{p o s}, \quad \mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{p o s} \in \mathbb{R}^{(N+1) \times D}\]이미지를 patch로 split하는 대신, CNN의 feature map에서 input sequence를 생성할 수도 있다. 이 모델을 하이브리드 모델이라고 부르는데, 이때는 아래의 방정식의 patch embedding projection E 가 CNN feature map에서 추출된 patch로 변경된다.
이 경우에는 patch로 1x1 의 spatial size를 사용하기 때문에 input sequence는 쉽게 flatten될 수 있다.
3.2 Fine-Tuning and Higher Resolution
일반적으로는 ViT를 large dataset에서 pre-training한 후, 더 작은 downstream task에 대해 fine-tuning한다.
pre-traing을 하는 것보다 높은 resolution으로 fine-tuning을 하는게 성능에 도움이 될때가 많다. 따라서 pre-trained prediction head를 제거하고 0으로 초기화된
D x K의 feedforward layer를 붙였다. (K는 downstream class)
만약 image의 화질이 높다면, sequence length는 더 길어질 것이다. 그런데 ViT는 제한된 길이의 sequence만을 처리할 수 있으므로 pre-trained position embedding이 더이상 의미가 없어지게 된다.
따라서 이 경우에는 pre-trained position embedding이 원본 이미지의 location에 따라 2D interpolation을 수행하도록 조정해준다.
4. Experiments
- Resnet, ViT, hybrid model을 평가
- 다양한 size의 data와 많은 benchmark task를 사용
이 논문의 저자들은 ViT가 더 낮은 pre-training cost로 대부분의 recognition benchmark에서 SoTA를 달성했다고 주장한다.
4.1 Setup
Datasets
Pre-train dataset
- ILSVRC-2012 ImageNet dataset(ImageNet) - 1k classes / 1.3M images
- ImageNet-21k - 21k classes / 14M images
- JFT - 18k classes / 303M images
Transfer Learning dataset
- ImageNet, cleaned up ReaL labels
- CIFAR 10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
Evaluate
- 19-task VTAB classification suite
Model Variants
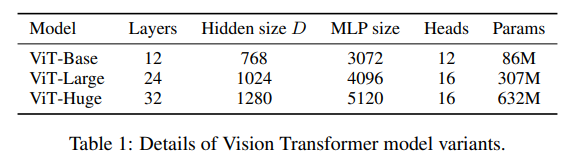
- base ViT configuration으로는 BERT와 유사하게 설정(Huge는 새로 추가)
- Vit-L/16 : L은 large, 16은 16 x 16 patch
CNN의 baseline으로는 ResNet을 사용했고, Batch Normalization layer대신 Group Normalization을 사용했다.
Training & Fine-tuning
Training
- Adam optimizer
- 논문의 실험에서는 Adam이 SGD보다 빨랐음
- β1=0.9, β2=0.999, batch_size=4096
- weight decay: 0.1
Fine-tuning
- SGD with momentum,
- Fine-tuning은 SGD사용
- batch_size=512
- using linear learning rate warmup and decay
- Higher resolution: 512 for ViT-L/16 and 518 for ViT-H/14
Metrics
downstream dataset는 few-shot이나 fine-tuning accuracy를 통해 평가한다.
보통 fine-tuning performance를 보지만 빠르게 결과를 보고 싶은 경우에는 linear few-shot accuracy를 보기도 한다.
4.2 Comparison to State of the Art
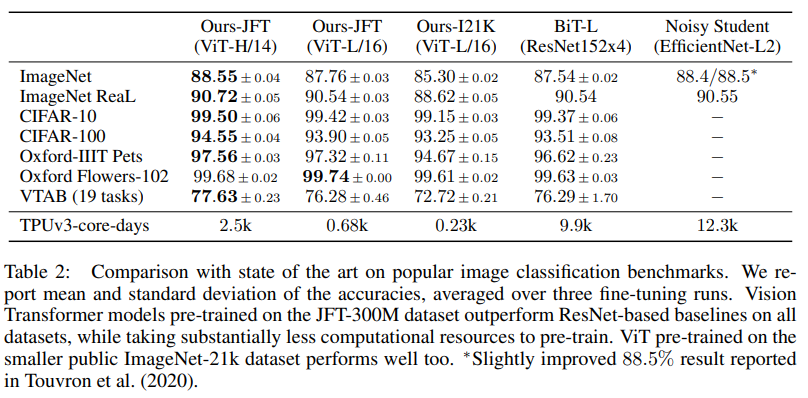
학습 시간과 결과이다.
- Big Transfer(BiT)는 large ResNet으로 supervised transfer learning을 수행했다.
- Noisy Student는 large EfficientNet으로 학습했다.
만개가 넘는 TPU를 써서 학습한 걸 보면, 역시 구글은 구글이다… 최근 NLP쪽 연구는 큰 규모의 회사가 아니면 못한다는 말이 맞는 것 같다,,
위의 결과는 BiT와 ViT를 비교한 내용인데 ViT가 BiT보다 더 적은 resource를 사용함에도 훨씬 더 좋은 성능을 내고 있음을 보여준다.
(개인적인 생각으로) JFT dataset은 구글에서만 사용되는 공개되지 않은 데이터셋인데, 이를 사용한 결과를 논문에 쓰는건 약간 애매한 것 같다 🤔
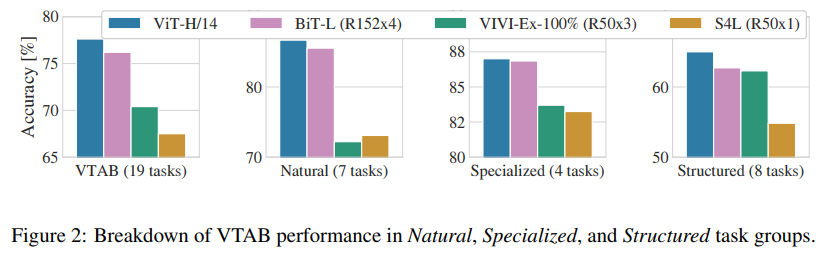 ](https://github.com/happy-jihye/happy-jihye.github.io/blob/master/_posts/images/nlp/vit2.PNG?raw=1](https://github.com/happy-jihye/happy-jihye.github.io/blob/master/_posts/images/nlp/vit2.PNG?raw=1))
](https://github.com/happy-jihye/happy-jihye.github.io/blob/master/_posts/images/nlp/vit2.PNG?raw=1](https://github.com/happy-jihye/happy-jihye.github.io/blob/master/_posts/images/nlp/vit2.PNG?raw=1))
큰 사이즈의 pre-trained data(ImageNet-21k와 JFT-300M)를 사용해서 실험을 했을 때, 이전 연구들과 비교해보면 ViT는 State of the Art 의 결과를 낸다 ! 😎
4.3 Pre-training Data Requirements
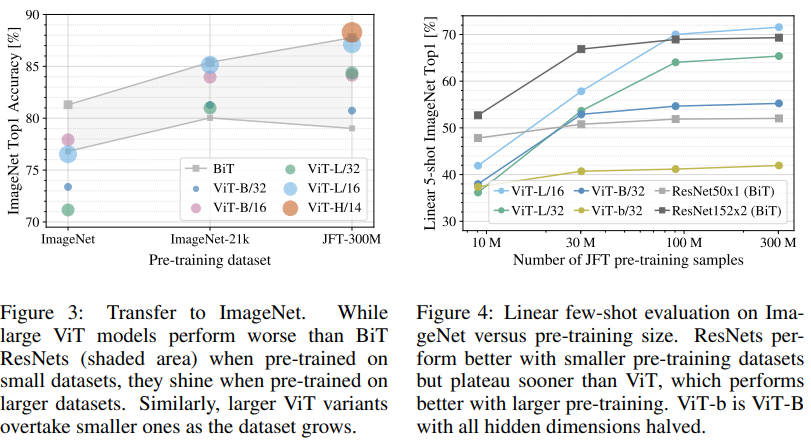
- small dataset에 대해서도 좋은 performance를 낼 수 있도록 weight decay, dropout, label smoothing의 세가지 regularization parameter를 optimize했다.
- ImageNet과 같은 작은 pre-trained dataset을 사용하면, 정규화를 많이 해도 ViT의 성능이 BiT보다 떨어진다. (Figure3)
-
이를 보면, ViT 모델은 큰 데이터셋에서만 좋은 성능을 냄을 확인할 수 있다.
- pre-training sample의 수가 적을 때에는 ViT의 성능이 ResNet보다 떨어진다.(Figure4)
-
Transformer는 CNN에 비해 inductive biases가 부족하기 때문에 학습데이터가 적은 경우에는 학습이 잘 안된다. 쉽게 말하자면 transformer는 CNN에 비해 이미지의 패턴을 학습하기 가 쉽지 않다. (translation equivariance나 locality를 학습하기가 어려움)
따라서 위의 결과처럼 transformer는 데이터셋의 크기가 클 때에 더 학습이 잘된다
-
4.4 Scaling Study
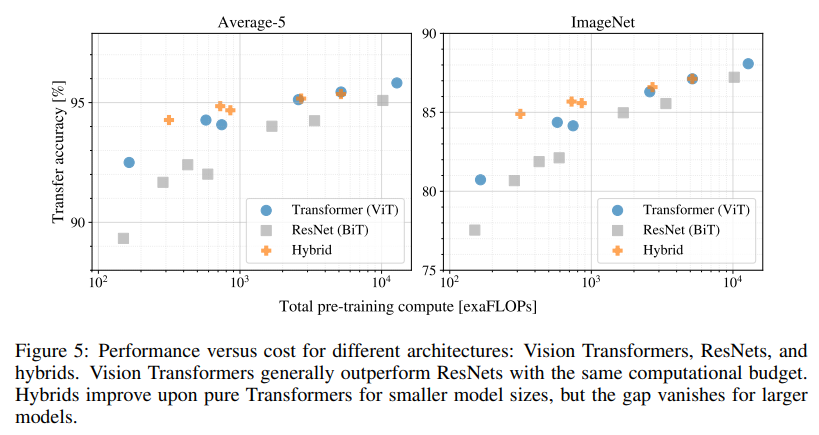
JFT-300M dataset을 통해 다양한 모델에 대해 scaling연구를 해보았다.
이때, data size는 모델의 성능에 병목현상이 되지 않으며 각 model의 pre-training cost 당 성능을 비교해본다.
- ViT는 전반적으로 ResNet보다 효율적 : performance/compute trade-off에서 2-4배 더 좋은 성능을 냄
- dataset의 크기가 작은 경우에는 Hybrid가 ViT보다 좋은 성능을 냄
4.5 Inspecting Vision Transformer
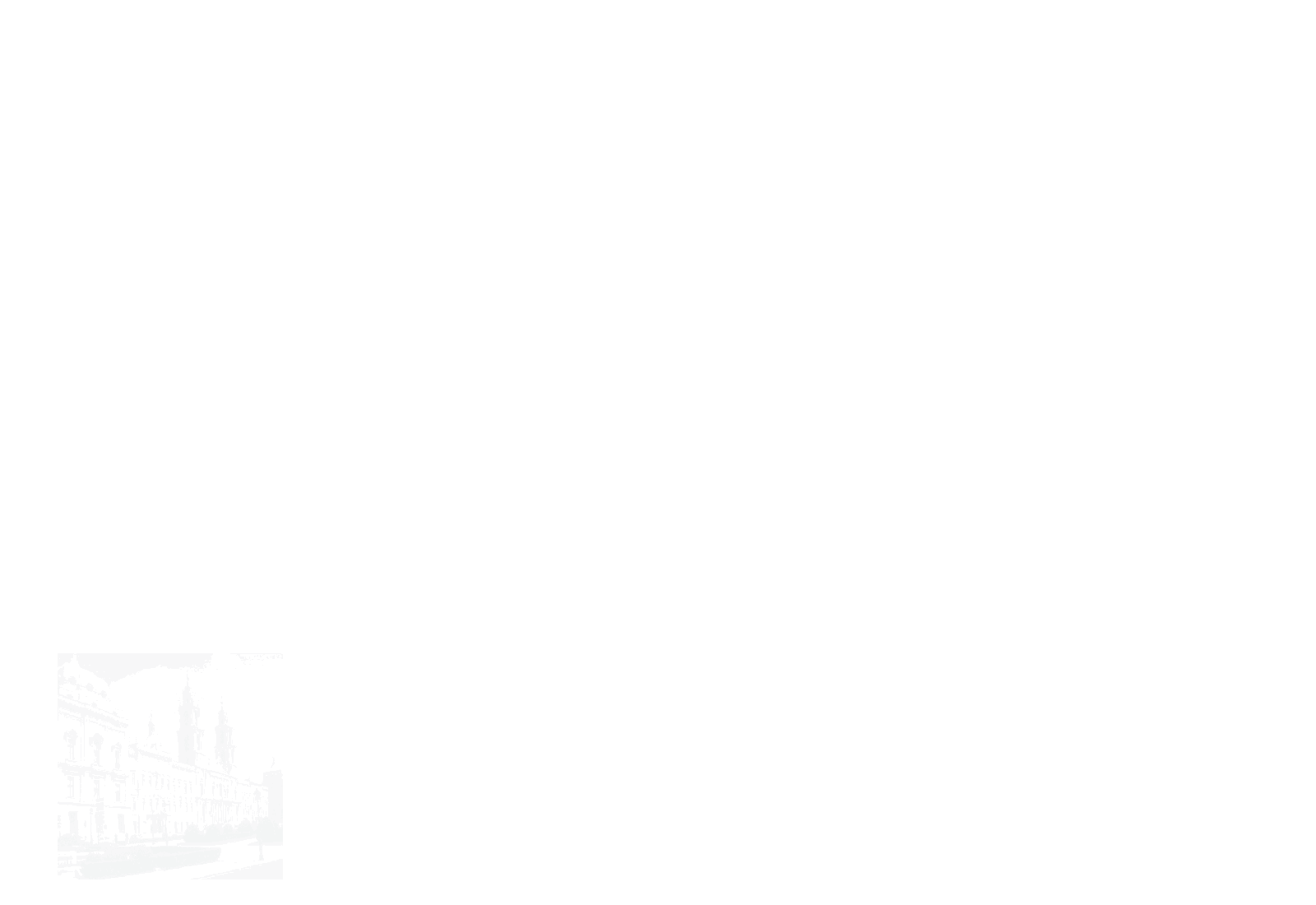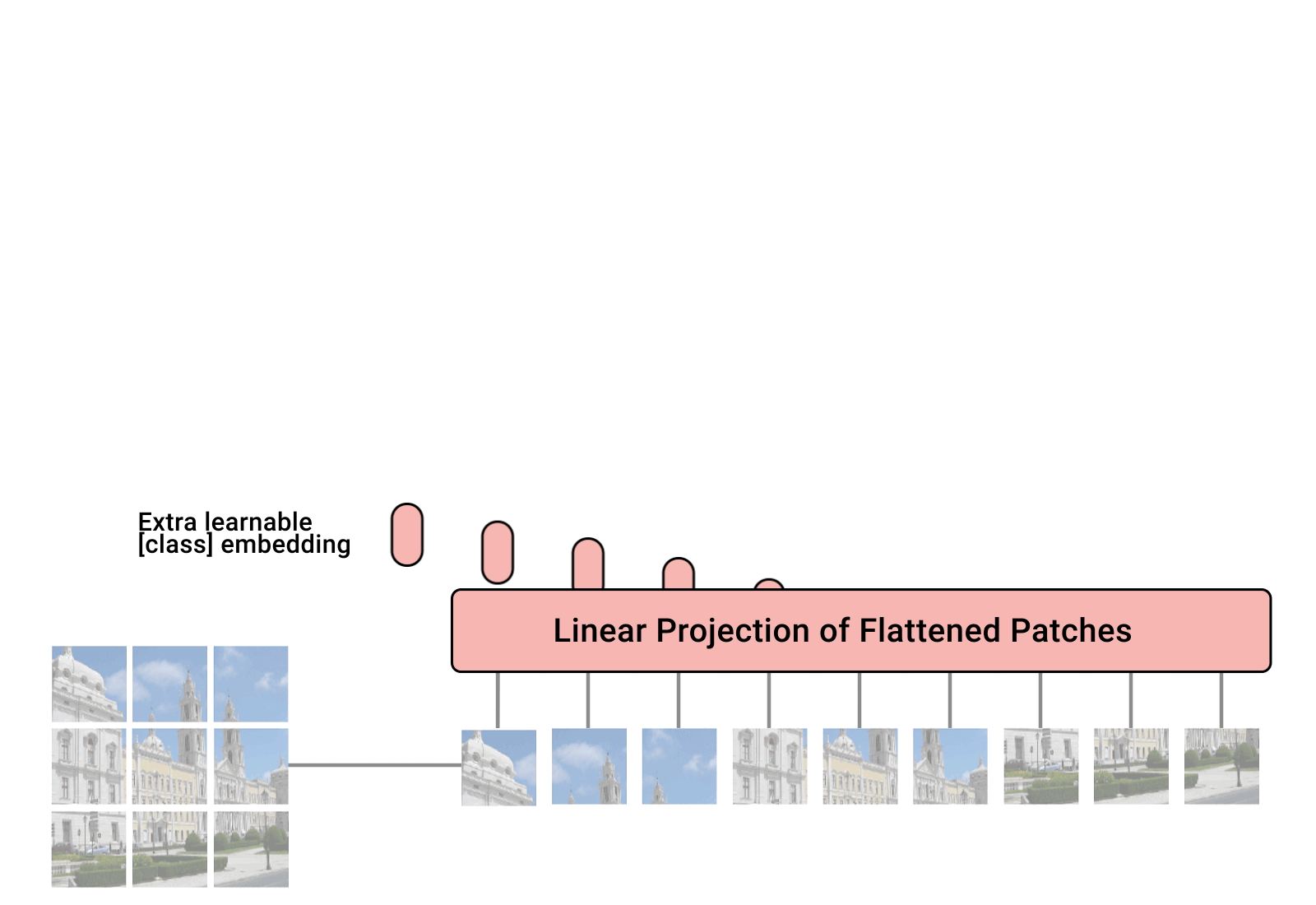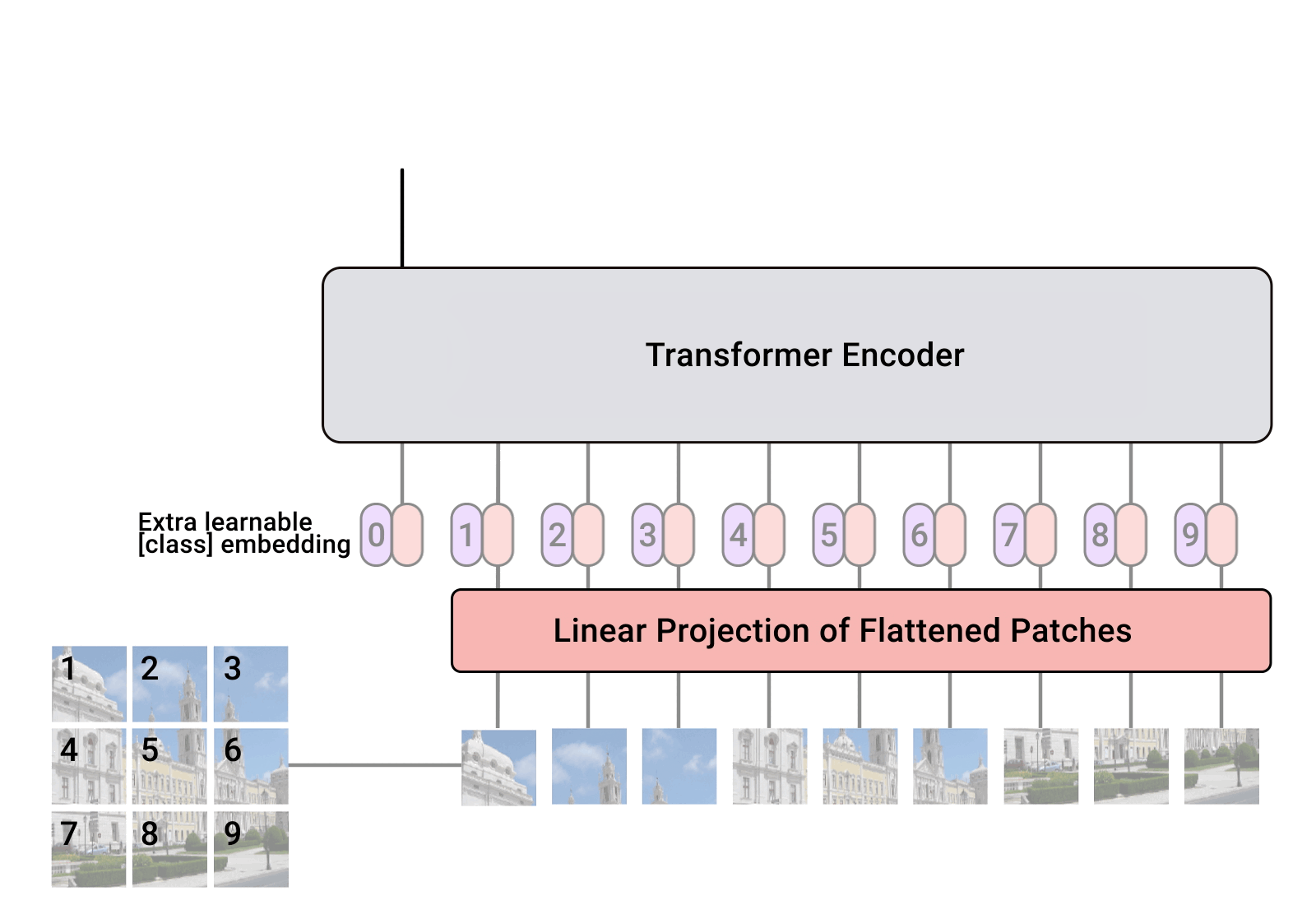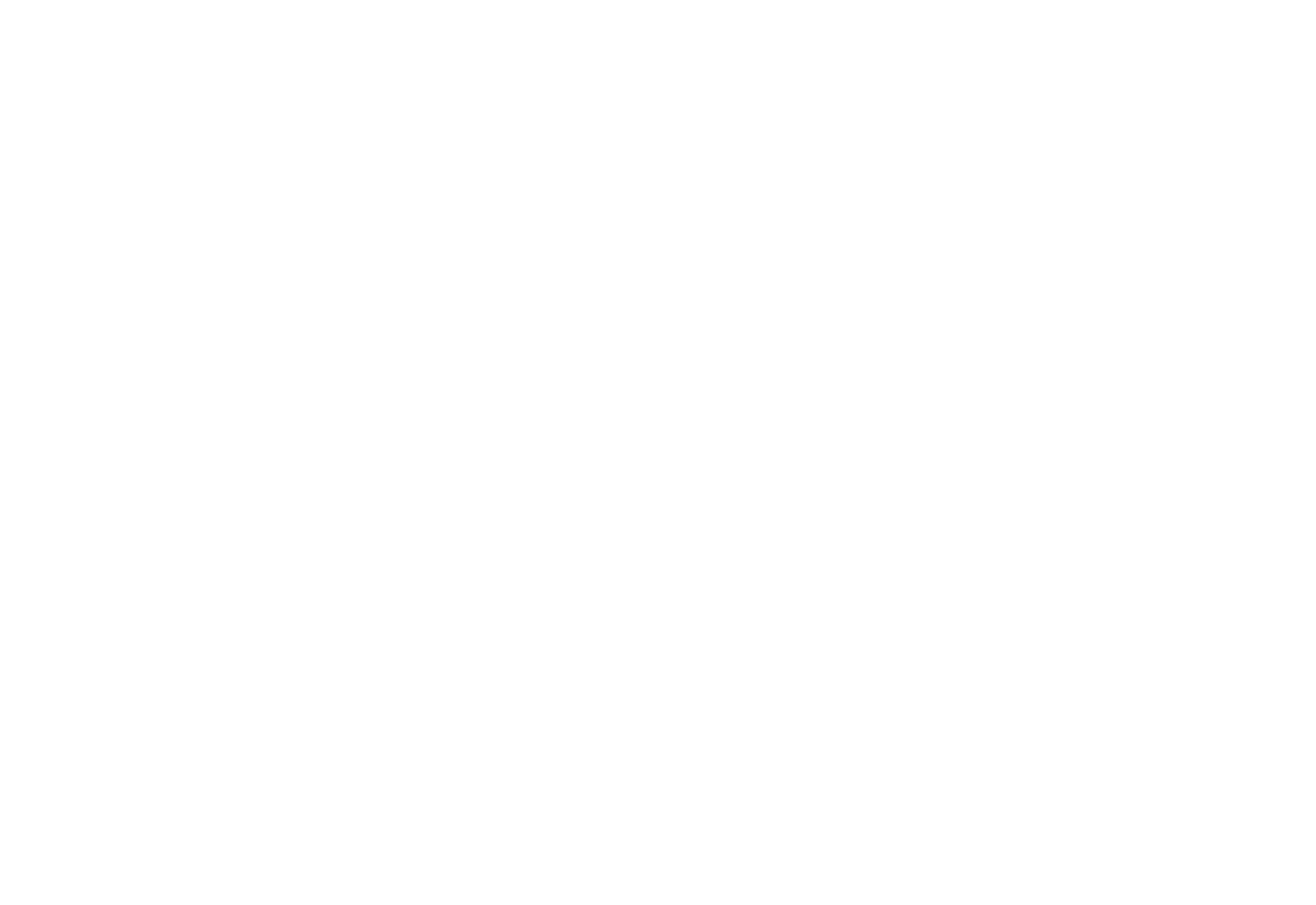
ViT는 다음과 같은 순서대로 이미지 데이터를 처리한다.
-
첫번째 layer는 flattened patch를 lower Dimension space으로 선형 투영한다.

Figure7의 왼쪽 그림은 학습된 embedding filter의 구성요소를 보여준다.
-
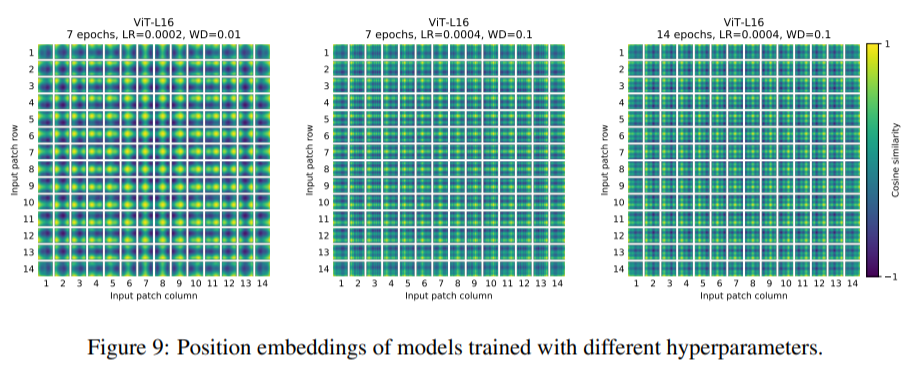
학습된 position embedding을 patch representation에 추가한다.
Figure7의 중간 사진을 보면 가까이에 있는 patch들의 position embedding이 비슷함을 확인할 수 있다.
-
Self-attention을 통해 하단의 layer부터 상단의 layer까지 전체 image에 대한 정보를 통합한다. 각 정보들을 모으면 image space에서 이미지간 평균 거리인 attention distance를 계산할 수 있다.
5. Conclusion
✍🏻 이 논문은 Transformer를 image recognition에 직접적으로 적용했다. Computer Vision에 self-attention을 적용한 이전의 연구들과는 달리, ViT에서는 architecture에 image-specific inductive biases를 적용하지 않았다. 대신 image를 patch단위로 쪼개 Transformer encoder에서 처리해줬다.
이와 같은 간단하면서도 확장가능한 model은 pre-training된 큰 데이터셋과 결합했을 때 아주 좋은 성능을 냈으며, 많은 image classification dataset에서 SoTA의 결과를 냈다.
남아있는 Challenge
- ViT를 detection이나 segmentation에 적용하는 연구
- pre-training methods
6. Opinion
🤔 이 논문은 Transformer를 Vision 분야에 적용했다는 점에서 의의를 가지는 거지, 딱히 획기적인 architecture를 제시하지는 못했다고 생각한다.(제시한 idea라고는 image patch정도?) 물론 SoTA의 결과를 냈기는 하지만, Google이 아니었으면 가능했을까? 싶기도 하고.. 많이 기대를 한 논문이었는데, parameter와 position embedding 정도만을 바꿔보면서 실험한게 다인 것 같아 아쉽다. 구글 만의 데이터셋인 JFT를 사용한 것도 그렇고..
관련 연구들이 더 다양하게 진행되어서 research의 규모가 크지 않더라도 학습이 가능한 경량화된 모델이 나왔으면 좋겠다
댓글남기기