
[CS231n] 5. Convolutional Neural Networks
업데이트:
Reference
- CS231n 강의노트 Convolutional Neural Networks
- Lecture 05 - ( Slide Link, ,Youtube Link )
- 🌺 Happy-Jihye / CS 231n 강의 노트
이 포스팅은 CS231n의 5강을 요약한 글입니다 😊

이번 강의에서는 CNN(Convolutional Neural Networks)에 대해 배웁니다.
CNN은 대표적인 이미지 처리를 위한 네트워크라서 많이들 아실 것 같아요. 만약 관련 예제를 다뤄보시고 싶으신 분들은 MINIST나 CIFAR-10 dataset을 이용한 CNN모델을 공부하시면 좋을 것 같습니다 :)
강의의 초반부에는 CNN의 역사도 간단하게나마 설명합니다. 이 글에서는 이에 대해는 생략하도록 하겠습니다.
Convolutional Neural Networks

이전 시간에는 Fully Connected Layer에 대해 배웠었습니다. FC Layer는 보통 vector를 길게 펴는 역할을 하며,위의 예제에서는 3072 차원의 길게 편 이미지를 가중치 벡터 W와 곱해서 10차원의 activation vector를 얻었습니다.
1. Convolution Layer

-
FC layer가 입력 이미지를 길게 폈다면, Convolution layer는 기존의 이미지 구조를 그대로 유지하게 됩니다. 즉, spartial structure를 유지한다고 볼 수 있습니다.
-
그리고 하늘색의 작은 Filter는 가중치 벡터의 역할을 하게 됩니다. 우리는 이 필터를 가지고 이미지를 슬라이딩하면서 공간적으로 내적을 하게 됩니다.
-
여기서 하나의 filter는 이미지의 아주 작은 부분이랑만 연산을 하지만, depth에 대해서는 input volume의 full depth에 대해 내적을 합니다.
1) Filter

| First filter(blue) | Second filter(green) |
|---|---|
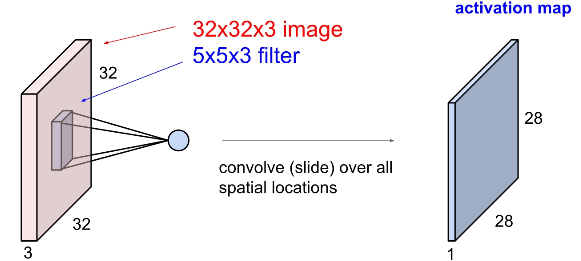 |
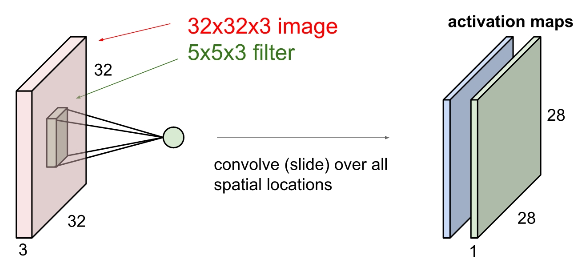 |

보통 Covolutional Layer에서는 여러 개의 필터를 사용합니다. 여러개의 필터를 사용함으로써 우리는 각 필터마다 다른 특징을 추출할 수 있게 됩니다.
위의 예제에서는 총 6개의 filter를 사용해서 6개의 activation map을 구했네요 :)
이때, 각각의 filter와 이미지의 spatial한 부분은 내적을 한다고 생각할 수 있습니다. 그렇기 때문에 activation map의 depth는 1이 됩니다.
(depth와 channel은 다른데, 보통 channel은 filter의 개수를 뜻합니다. 이는 후반부에 설명하겠습니다😊)
2) ConvNet

Conv layer와 Relu와 같은 여러 activation function을 사용하여 CNN을 구성할 수 있습니다.

앞서 하나의 Conv layer 는 여러 개의 filter를 가지며 이는 각각의 출력 map을 만든다고 했는데요,
여러개의 Conv layer를 쌓게 되면 각 filter들은 계층적으로 학습을 하게 됩니다.
- 위의 예제에서 앞쪽의 filter들은 edge와 같은
low-level feature를 학습하게 되고, - 중간의 filter들은
mid-level feature을 학습하고 - 후반부의 filter는
high-level feature을 학습합니다.
즉, 계층적 구조를 설계하고 역전파를 통해 학습시키다보면 filter는 네트워크의 앞쪽에서는 단순한 것들을 처리하고 뒤로 갈수록 점점 복잡한 것들을 처리하도록 학습됩니다.
Example of Activation map

맨 위의 사진은 32개의 5x5 filter들을 시각화한 것입니다.
필터를 슬라이딩 시키면서 학습을 하면 필터와 비슷한 값들은 더 커지게 되며, 결과값으로 activation이 나옵니다. 이 activation는 단어 그대로 어느 위치에서 이 필터가 크게 반응하는지를 보여줍니다.

다음은 CNN이 어떻게 수행되는지를 나타낸 그림입니다.
Conv Layer후에는 activation func를 거치게 되고, 이로는 Relu function을 가장 많이 사용합니다.
여러 개의 Conv-Relu layer들을 거치면 pooling layer를 거치게 되며 pooling은 activation maps의 사이즈를 줄이는 역할을 합니다. 마지막은 FC-Layer로 우리가 지난 4강에서 배운 layer입니다. 이 레이어는 모든 Conv출력과 연결되어있으며 최종스코어를 계산하기 위해 사용합니다.
3) Filter
다시 돌아와서 filter 입니다.


다음은 filter가 어떻게 슬라이딩을 하면서 input값을 처리하는지를 그림으로 나타낸 예제입니다.

- https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
예를 들어 stride가 1이라면 다음과 같이 움직입니다.
즉, 위의 예제에서(7x7 input, 3x3 filter) stride가 2이라면 3x3 의 output이 출력됩니다.
이때 같은 예제에서 stride가 3이라면 어떻게 될까요?

output이 생성되지 않습니다 !
따라서 이 경우에는 padding 을 해서 stride가 맞지 않는 경우에도 정수차원의 output이 생기도록 만들어줍니다.
위의 output size 공식은 중요하니 잘 봐두시길 바랍니다 :)
4) Padding


다음의 예제에서 output은 7x7x3이 될까요, 7x7x1이 될까요?
- 정답은 7 x 7 x “필터의 개수” 입니다.
- 각 filter가 모든 depth에 대해 내적을 취하기 때문에 각 filter의 결과값은 7 x 7 x 1이며, activation map의 depth는 filter의 개수가 됩니다.
padding의 종류로는 zero-padding 말고도 여러 개가 있습니다. 이에 대해서는 다음에 더 자세히 설명드리겠습니다. 또한, padding을 하는 이유는 보통 사이즈를 유지하고 싶기 때문입니다.
filter를 걸쳐 계산을 하면 output의 size가 대게 줄어드는데, 여러번 학습을 해도 이미지의 사이즈를 줄이고 싶지 않은 경우에 padding을 사용하곤 합니다.

즉, padding을 하지 않는다면 매번 각 코너에 있는 값들을 계산하지 못하기 때문에 activation map의 사이즈는 계속해서 줄어들 것입니다.
따라서 우리는 padding을 통해 출력 사이즈를 유지시켜주며 필터의 중앙이 닿지 않는 곳에서도 연산을 할 수 있게 됩니다.

⭐ Filter당 파라미터의 개수를 셀 때 bias term도 있다는 걸 주의하세요 !

5) 1 x 1 Convolution layer

우리는 1 x 1의 conv layer도 사용하곤 합니다. 이때는 5x5 conv layer처럼 공간적인 정보를 이용하지는 않지만,여전히 depth만큼의 내적 연산을 수행하기 때문에 출력으로는 56 x 56 x 32가 나옵니다.
Exampe : Conv layer
| Torch | Caffe |
|---|---|
 |
 |


Conv Layer는 하나의 뉴런은 한 부분만 처리하고 그런 뉴런들이 모여서 전체의 이미지를 처리한다는 점에서 신경망과 매우 유사합니다.
우리는 Conv Layer를 사용하여 spatial structure을 유지한 채로 layer의 출력인 activation map을 만들 수 있습니다.

위의 파란색은 output입니다. filter가 총 5종류라면 output의 depth는 5개 되며, 이 5개의 점은 같은 지역에서 추출된 서로 다른 특징들이라고 보시면 됩니다.
2. Pooling Layer

pooling layer가 하는 일은 간단합니다. 이미지를 공간적으로 Downsample합니다. (pooling은 출력 사이즈를 줄이기 위한 기법이므로 보통 padding을 사용하지 않습니다.)
pooling layer는 depth에는 영향을 주지 않으며, Max-pooling을 가장 많이 사용합니다.

pooling layer에서도 filter를 사용합니다. pooling은 기본적으로 downsample을 하기 위한 layer이므로 겹치지 않게 설정을 하며, 우리는 filter의 크기만큼 input layer을 지역적으로 살펴보곤 합니다.
avg pooling도 사용하지만 Max pooling은 그 지역이 어떤 신호에 대해 얼마나 활성화되었는지를 알려주는 지표이므로, 보통 max pooling을 많이 사용하곤 합니다. (그 값이 어디에 있었는지 보다는 얼마나 큰지가 중요)
사실 pooling이나 stride나 하는 일은 비슷합니다. 요즘은 그래서 stride를 pooling 대신으로 사용하곤 합니다.(성능이 더 좋기도)
3. Fully Connected Layer (FC layer)

FC Layer에서는 3차원의 출력값을 전부 stretch해서 1차원의 vector로 만듭니다. 즉, 이 layer부터는 spatial structure을 고려하지 않고 score로 최종적인 추론을 하게 됩니다.
-
다음은 CIFAR-10의 demo입니다.
https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
⭐ Summary
- ConvNets은 CONV, POOL, FC layers를 쌓아 올려서 만들어집니다.
- 네트워크의 filter는 점점 작아지고, architecture의 depth는 점점 깊어집니다.
- 최근에는 POOL/FC layer를 없애고 CONV layer만을 깊게 남기는 추세입니다.
예전에 학교 프로젝트에서 verilog 로 CNN Accelerator(가속기)를 만든 적이 있었는데, 관련 내용도 기회가 되면 포스팅 하겠습니다 :)
그럼 저희는 6강에서 뵙겠습니다. 궁금한 점이 있으시다면 댓글 남겨주세요 😊
댓글남기기