
딥러닝 모델 배포하기 #01 - MLOps PipeLine과 연산 최적화 / 모델 경량화
업데이트:
Python 과 ML/DL
Python은 굉장히 재미있는 언어다. 언어가 정말로 직관적이며 가독성이 좋다. 때문에 C 계열의 언어나 java만을 사용하던 나에게는 묘한 거부감을 주던 언어였다. 초기에는 야매 프로그래밍 같다는 인상을 받았다.
파이썬은 머신러닝/딥러닝 알고리즘 구현을 위해 가장 선호되는 언어 중 하나다. 이는 script language, dynamic typing, Multi paradigm 등 파이썬 언어 자체가 사랑받는 본연의 특징들 때문이기도 하고, 딥러닝에 필요한 복잡한 수학적 연산들을 구현하기 쉬운 탓도 있다. 또, 파이썬은 방대한 라이브러리 생태계를 기반으로 하기 때문에 머신러닝 연구자에게는 정말로 편리하다.
다만, python은 굉장히 느리며 GIL(Global Interpretor Lock)로 인해 Multi-threading 성능에 제약이 있다. 이 때문에 production 환경에서 flask나 django와 같은 python 웹서버를 통해 서비스를 한다면, request throughput 및 GC로 인해 지나치게 서버가 느려질 수도 있다.
Model Serving, MLOps
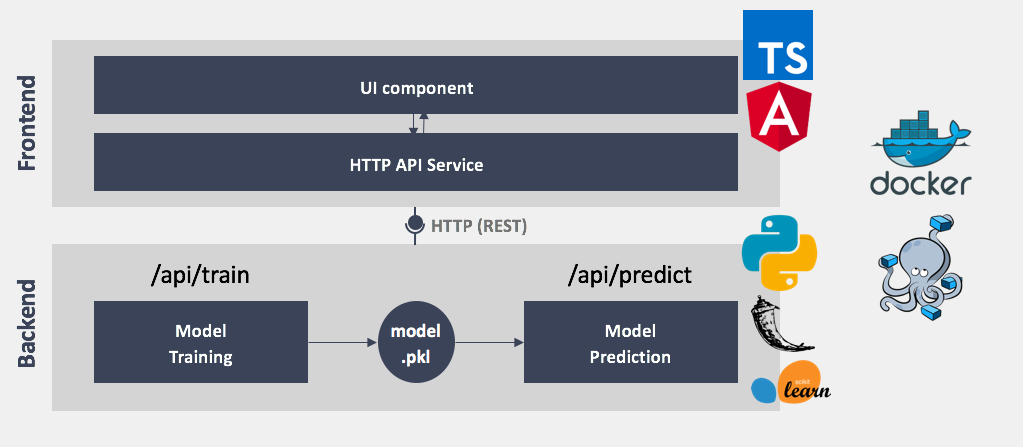
모델을 서빙하고, 이를 서비스화하는 것은 더욱더 어려운 문제다. 보통 딥러닝 모델은 다음과 같은 파이프라인을 통해 서비스화되는데, 제대로된 ML/DL 모델을 만드는 것도 매우 어렵지만, 연산에 많은 resource가 필요한 모델을 서빙하는 것은 더 어려운 문제이기 때문이다.

MLOps 수준 0: 수동 프로세스 (출처: MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인)
최근에는 머신러닝(ML)을 지속적으로 배포하고 자동화하게 해주는 MLOps에 대한 연구도 활발히 진행되고 있다. 그러나 본 포스팅은 MLOps 보다는 ML 모델의 Production화 자체에 초점을 맞춰 MLOps 수준 0 에서 모델을 경량화하고 연산을 최적화시켜 모델을 서비스하는 것에 중점을 두어 설명하고자 한다.
참고할 만한 글 ✍🏻
FrameWork
Pytorch
최근들어 research 분야에서는 pytorch가 자주 사용되는 추세이다. 이는 Pytorch가 python과 굉장히 결이 비슷한 프레임워크여서 연구자들에게 보다 친숙하기 때문이라고 생각한다. dynamic하며 간단 명료하고, debuggable, hackable(use any python library)하다.
또, AI 연구는 오픈소스를 기반으로 발전하고 있기 때문에 다른 사람이 만들어놓은 코드를 쉽게 가져올 수 있다는 점이 pytorch를 더 유명하게 만들지 않았나.. 추측한다.
tensorflow

다만, 모델 배포나 상품 구축과 같은 production 분야에서는 tensorflow가 훨씬 더 자주 사용된다. tensorflow 자체가 pytorch보다는 모델에 optimize가 잘되기도 하고, tensorflow-light가 나오면서 모델을 쉽게 배포할 수 있게 된 탓이다.
Tensorflow 생태계가 얼마나 잘 구축될지, 또 얼마나 TPU가 AI 학습에 있어서 자주 사용될지가 tensorflow의 미래를 결정할 것 같다. 아마 구글이 Tensorflow-RT랑 TPU 하드웨어 시장을 키우려고 노력하는 만큼, 엔비디아가 페이스북이랑 손을 잡고 GPU + Pytorch를 열심히 키울 것 같아서.. 어느 쪽 프레임워크가 미래에 더 많이 사용될지는 모르겠다.
연산 최적화
모델을 학습하여 배포하고 나면, 서비스 단계에서는 model inference가 필요하다.
Model Inference 자체에도 많은 행렬 연산이 필요한데, 이를 위해 CPU 단계에서는 MLD, MKL-DNN 등의 라이브러리를, GPU 단계에서는 TensorRT, TorchScript & JIT 등을 이용하여 연산을 최적화하곤 한다.
MKL-DNN
Intel에서 만든 딥러닝 라이브러리이다. (Math Kernel Library for Deep Neural Networks) MKL-DNN을 활용하여 최적화시킨 Pytorch와 Tensorflow 를 사용하게 되면 속도가 굉장히 빨라진다고 알려져있다. (link)
예전에 하드웨어 연구실에서 딥러닝용 accelerator 연구할 때 관련 실험을 좀 했었는데.. 성능이 꽤 많이 좋았던 걸로 기억한다.
TensorRT
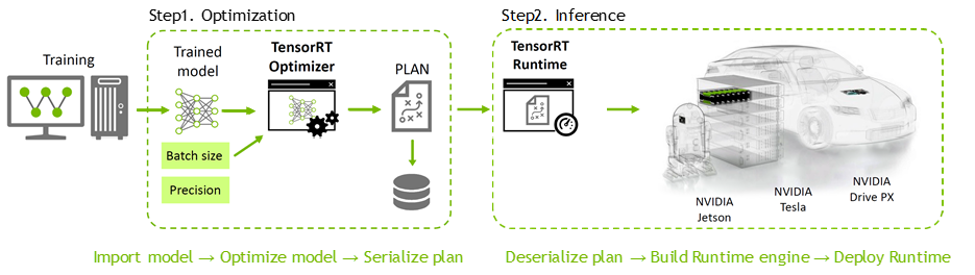
TensorRT는 학습된 Deep Learning 모델을 최적화하여 NVIDIA GPU 상에서의 Inference 속도를 수배 ~ 수십배 까지 향상시켜주는 모델 최적화 엔진이다. (출처: NVIDIA)
대부분의 Deep Learning Frameworks(Tensorflow, Pytorch, keras, onnx)에서 학습된 모델을 지원하며, CUDA 지식이 별로 없어도 쉽게 사용할 수 있다.
최근에는 Torch-TensorRT, TensorFlow-TensorRT, Onnx-TensorRT 등 다양한 조합이 사용된다.
- ONNX (Open Neural Network Exchange): Facebook(Meta)와 MS에서 개발한 딥러닝 모델의 호환 포멧으로, 특정 프레임 워크에서 작성한 모델을 다양한 모델로 변환시켜줌.
- 예를 들어,
Pytorch➡ONNX 변환➡Tensorflow의 변환이 가능 - ONNX 모델을 사용하면 여러 다양한 플랫폼과 하드웨어에서의 효율적인 추론을 가능해진다. 따라서 pytorch 모델을 tensorrt를 통해 최적화하고자 할 때, 바로
pytorch에서TensorRT로 변환하지 않고,Pytorch➡ONNX 변환➡TensorRT의 과정을 통해 변환하기도 한다.
- 예를 들어,
TorchScript & Pytorch JIT
Pytorch는 Python과 최대한 유사하게 만들어진 프레임워크이기 때문에, Tensorflow에 비해 모델을 서빙하기에 부족하다. Facebook(Meta)가 이러한 한계를 바로잡고자 내놓은 것이 TorchScript와 Pytorch JIT인데, 이를 사용하면 모델을 최적화하여 다양한 환경에서 serving 하는 것이 가능해진다.
TorchScript & Pytorch JIT 에 대한 자세한 설명은 다음 포스팅 (2편)에서 ☺
모델 경량화
연산 최적화와 달리 모델 경량화는 학습 과정에서 이루어진다. 모델을 경량화하여 학습시킬 경우, GPU resource, 메모리 등의 측면에서 이점이 있기 때문에 최근 많이 연구되고 있다.
모델 경량화에는 크게 세가지 방법이 있다.

- Pruning (가지치기)
- 신경망 학습에서 중요도가 떨어지는 node를 제거하고 재학습하는 과정을 반복하여 모델의 크기를 줄여나가는 방식
- 이 방식을 통해, Deep Compression (2015) 논문에서는 VGG-16 model을 약 49배 경량화 하였으며, Clip-q (2018)에서는 ResNet-50 model을 약 15배 경량화하였다고 한다.
- Knowledge Distillation (지식 증류)
- 학습이 잘된 큰 딥러닝 모델(Teacher model)의 지식을 학습되지 않은 작은 크기의 모델(student model)에게 가르쳐줄 수 있지 않을까? 에서 시작한 방법론
- Quantization (양자화)
- 모델의 해상도를 낮춰 작게 만드는 방법
- 파라미터의 Precision을 적절히 줄여서 연산 효율성을 높임
마치며..
대기업에 있으며.. 모델을 연구/개발하는 것뿐만 아니라 이를 서비스화하는 것까지 많은 과정들을 지켜볼 수 있었다. 모델을 연구/개발하는 것 뿐만 아니라 서빙하는 것도 굉장히 어렵고 시간이 오래 걸리는 문제이기 때문에, AI Researcher로서 MLOps의 파이프라인뿐만 아니라 모델의 경량화 및 연산 최적화까지 꼭 알아야 하는 문제임을 체감하고 있다.
언젠가 곧 내가 연구/개발한 모델도 서비스화되기를 !
reference
- MLOps 란 무엇일까?
- MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인
- PyTorch JIT and TorchScript
- TorchScript and PyTorch JIT / Deep Dive
- How to Convert a Model from PyTorch to TensorRT and Speed Up Inference
- Torch-TensorRT
- 딥러닝 모델 서비스 A-Z 1편 - 연산 최적화 및 모델 경량화
- NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit
- pytorch 모델 저장과 ONNX 사용
- Torch-TensorRT
댓글남기기