
[Paper Review] StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery 논문 분석
업데이트:
✍🏻 이번 포스팅에서는 text로 이미지를 조작하는 StyleCLIP에 대해 살펴본다.
-
Paper : StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (arXiv 2021 /Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, Dani Lischinski)
1. Introduction
그동안의 Image manipulation은 사용자가 직접 의미있는 latent space를 찾은 후 sementic direction을 찾아 control하는 방식으로 진행되었다.

StyleGLIP은 StyleGAN과 CLIP model을 기반으로 text기반의 이미지를 생성한 모델이다. 이전 모델들보다 훨씬 직관적이며, latent space를 일일이 찾지 않아도 text에 따라 이미지 조작이 가능하기 때문에 발표되자마자 많은 주목을 받은 논문이다.
- StyleGAN
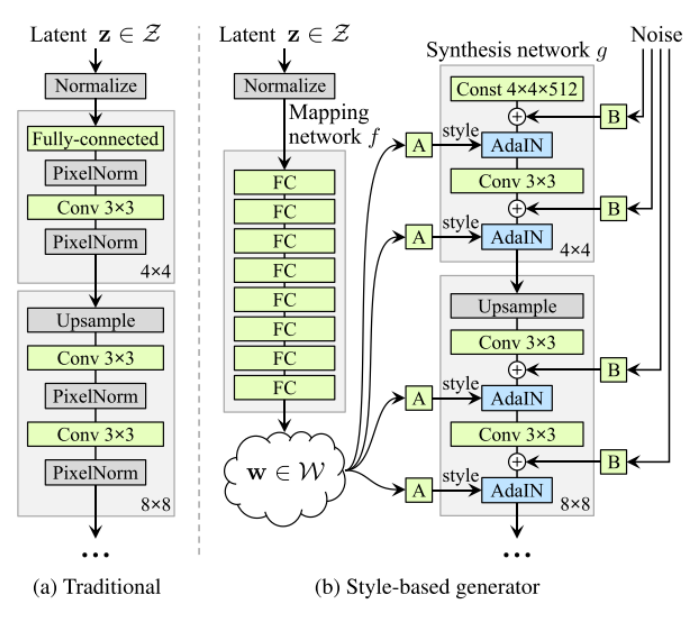
- StyleGAN은 global attribute와 style을 잘 학습시킨 모델으로, 이미지 생성에 있어 latent space의 역할이 무엇인지를 잘 설명했다.
- [Paper Review] StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks 논문 분석
- [Paper Review] StyleGAN2 : Analyzing and Improving the Image Quality of StyleGAN 논문 분석
- CLIP(Contrastive Language-Image Pre-training)

-
CLIP은 multi-modal embedding space를 학습하여 text와 image사이의 semantic similarity를 추정하였다. 인터넷에서 크롤링한 400M(4억개)의 text-image pair를 이용하여 representational learning을 수행하였고, zero-shot image classification에서 SOTA의 결과를 냈다. (ImageNet에 대해 zero-shot learning를 test 하였을 때에는 76.2%의 매우 높은 결과가 나왔다. 이를 통해 학습 과정에서 한번도 보지 못한 문제 및 데이터셋에 대해서도 좋은 성능을 내고 있음을 확인할 수 있다.)
-
Image Encoder로는 Vision Transformer(ViT)를, Text Encoder로는 Transformer를 사용하였으며, 이를 통해 이미지와 텍스트 사이의 관계를 학습할 수 있다.
- Paper Review : Vision Transformer, Transformer
-
2. Related Work
Text-guided Image Generation and Manipulation
- Generative Adversarial Text to Image Synthesis
- text2image의 초기 연구로, conditional GAN을 이용하여 text에 따라 이미지를 조작하였다.
- AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks
- Attention mechanism을 통해 text와 image 사이의 관계를 정의하여 text-to-image generation을 수행하였다.
- TediGAN: Text-Guided Diverse Face Image Generation and Manipulation
- text와 StyleGAN의 latent space를 mapping하는 encoder를 학습하여 text에 따라 이미지를 조작하였다.
3. StyleCLIP Text-Driven Manipulation
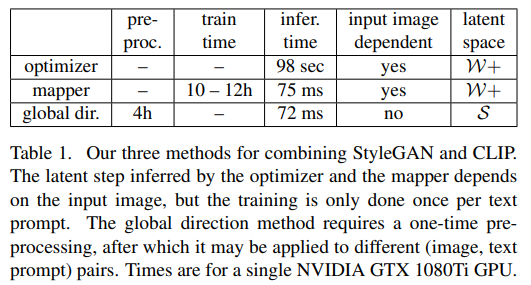
StyleCLIP은 Text-Driven Image Manipulation을 위한 세가지 방법을 제안한다.
(1) Text-guided latent optimization : CLIP model의 loss network를 도입하여 text를 바탕으로 input latent vector를 수정할 수 있도록 함 (StyleGAN의 $\mathbf{W+}$ space의 Image latent vector와 CLIP space의 Text latent vector의 loss를 최소화하도록 optimize를 함)
Text-guided latent optimization, where a CLIP model is used as a loss network. This is the most versatile approach, but it requires a few minutes of optimization to apply a manipulation to an image.
(2) Latent Residual Mapper
A latent residual mapper, trained for a specific text prompt. Given a starting point in latent space (the input image to be manipulated), the mapper yields a local step in latent space.
(3) text에 따라 StyleGAN의 style space에서 Input-global(agnostic) direction를 조정하는 mapping network
A method for mapping a text prompt into an inputagnostic (global) direction in StyleGAN’s style space, providing control over the manipulation strength as well as the degree of disentanglement.
3.1 Latent Optimization
- Text-guided latent optimization : CLIP model의 loss network를 도입하여 text를 바탕으로 input latent vector를 수정할 수 있도록 함 (StyleGAN의 $\mathbf{W+}$ space의 Image latent vector와 CLIP space의 Text latent vector의 loss를 최소화하도록 optimize를 함)
(1) pretrained & fixed StyleGAN의 Generator $G$와 (2) CLIP의 image encoder에서의 gradient descent를 통해 latent code를 optimization한다.
\[\underset{w \in \mathcal{W}+}{\arg \min } D_{\mathrm{CLIP}}(G(w), t)+\lambda_{\mathrm{L} 2}\left\|w-w_{s}\right\|_{2}+\lambda_{\mathrm{ID}} \mathcal{L}_{\mathrm{ID}}(w)\]- $D_{\mathrm{CLIP}}(G(w), t)$ : 우리가 입력한 text prompt $t$와 유사한 이미지가 생성하도록 조작하는 CLIP Loss이다.
- $G$ : pretrain된 StyleGAN의 Generator
- $D_{\mathrm{CLIP}}$ : 생성된 이미지 $G(w)$와 text의 CLIP embedding간의 cosine distance
- $\lambda_{\mathrm{L} 2}\left|w-w_{s}\right|{2}+\lambda{\mathrm{ID}} \mathcal{L}_{\mathrm{ID}}(w)$ : L2 Distance와 Identity Loss로, 조작된 image가 input 이미지와 비슷하도록 loss를 update하는 부분

- optimization을 200~300회 반복한 후의 그림.
- $\mathcal{L}_{\mathrm{ID}}$를 낮게 설정하면 이미지의 identity를 조정할 수 있음
3.2 Latent Mapper
- 3.1 Latent Optimization은 이미지 조작은 잘 하지만, 이미지를 조작하려면 (image, text) single pair 마다 몇분의 optimization과정이 필요하기 때문에 여러장의 이미지를 학습시키기엔 시간이 너무 오래걸림
- $\lambda$ 와 같은 parameter에 sensitive함 → 한번 훈련을 해놓으면 그 이후부터는 inference만 하면 되는 3.2 Latent Mapper를 제안 !

Architecture
- 세가지의 layer group : Coarse, Medium, Fine
- 각각의 그룹은 서로 다른 latent vector와 FC-layer를 가짐
-
StyleGAN에서는 8개의 FC-layer를 통해 latent code $z$에서 immediate latent code $w$를 만들었다면 StyleCLIP에서는 4개의 FC-layer를 사용하여 latent code $w$를 만듦 \(w = (w_c, w_m, w_f)\)
-
각각의 Latent vector들을 Mapping하여 Manipulation step $M_{t}$를 만
\[M_{t}(w)=\left(M_{t}^{c}\left(w_{c}\right), M_{t}^{m}\left(w_{m}\right), M_{t}^{f}\left(w_{f}\right)\right)\]
Loss Mapper는 input image의 global attribute를 유지하면서 text prompt, $t$에 따라 manipulation되도록 훈련된다.
\[\mathcal{L}(w)=\mathcal{L}_{\text {CLIP }}(w)+\lambda_{L 2}\left\|M_{t}(w)\right\|_{2}+\lambda_{\text {ID }} \mathcal{L}_{\mathrm{ID}}(w)\]-
CLIP loss
\[\mathcal{L}_{\text {CLIP }}(w)=D_{\text {CLIP }}\left(G\left(w+M_{t}(w)\right), t\right)\]
Latent Mapper은 초기 훈련시간이 10시간 이상으로 오래 걸리지만, 한번 훈련시켜놓으면 이를 추론시에 계속 사용할 수 있다는 장점이 있다.

훈련 결과도 성공적이다. identity를 유지하면서 text에 따라 visual attribute를 조절할 수 있다.

또한, text prompt를 통해 여러 가지의 속성을 한번에 바꿀 수도 있다.
3.3 Global Directions
3.2의 Latent Mapper는 inference time은 빠르지만, 세밀하게 disentangle manipulation을 조절하는데 부족함이 있다. 또한, text prompt가 주어졌을 때 manipulation step의 방향이 다양하지 않고 비슷할 때도 많다.
따라서 이를 해결하기 위해 text prompt를 StyleGAN의 style space $S$의 single, global direction와 mapping하는 방법을 제안하였다. 이렇게 하면 다른 latent space보다 조금 더 disentangle해지기 때문에 세밀한 조절이 가능하다.
- style code $s \in \mathcal{S}$에 따른 이미지를 생성한다. $G(s)$
- text prompt가 주어지면, CLIP text encoder를 사용하여 CLIP’s joint language-image embedding vector인 $\Delta t$를 구한다.
- $\Delta t$를 manipulation direction에 따라 $\Delta s$ vector로 mapping한다.
- manipulation strength는 $\alpha$를 조절함으로써 조정할 수 있으며, 생성된 이미지는 $G(s+\alpha \Delta s)$ 이다.

출처 : 나동빈님 StyleCLIP 자료
direction에 따라 각기 다른 style로 image를 manipulation할 수 있다.

darker hair라는 direction($\Delta t$)이 있을 때, manipulation strength $\alpha$를 조정함으로써 스타일의 정도를 조절할 수 있다.

다양한 dataset에서 global direction을 통해 Text-Driven Manipulation를 할 수 있다.
4. Comparisons & Evaluations
Text-Driven Manipulation Methods

TediGAN과 비교했을 때 StyleCLIP이 더 좋은 이미지를 생성한다.
Other StyleGAN manipulation methods

StyleCLIP은 다른 styleGAN manipulation method보다 간단한 방식으로 latent space를 조정하지만 생성된 이미지의 quality는 비슷하다.
Limitations
StyleCLIP은 pretrained StyleGAN generator와 CLIP model for a joint language-vision embedding를 바탕으로 만들어졌다. 따라서 Generator가 pretraining되지 않은 영역에 대해서는 이미지 조작이 어렵다. 또한, text prompt 역시 CLIP space외의 영역에 mapping된다면 의미있는 visual manipulation을 할 수 없을 것이다.
5. Conclusions & Opinion
✍🏻 그래도 StyleCLIP은 비교적 간단한 방식으로 text에 따라 이미지를 manipulation한 효과적인 모델이다. 최근 들어서는 pretrained model을 fine-tuning하여 의미있는 결과를 내는 것이 트렌드이기 때문에 더 주목을 받지 않았나싶다.
Conclusion : 본 논문은 StyleGAN과 CLIP을 결합한 세가지의 image manipulation method를 제안했다. CLIP을 잘 활용하면 세밀한 control도 가능하며, StyleCLIP에서는 disentanglement 정도와 manipulation strength도 조절할 수 있다.
Reference
댓글남기기