
[Paper Review] Towards Controllable and Photorealistic Region-wise Image Manipulation 간단한 논문 리뷰
업데이트:
- Paper: Towards Controllable and Photorealistic Region-wise Image Manipulation (ACMMM 2021): paper
- GAN-Zoos! (GAN 포스팅 모음집)
Towards Controllable and Photorealistic Region-wise Image Manipulation
- Code consistency loss를 통해 기존 모델보다 style과 content를 disentangle하게 학습할 수 있도록 함
- Content alignment loss를 사용하여 특정 annotation 없이도 self-supervised하게 region-wise stylization을 학습할 수 있도록 함
기존의 Swap AE는 좋은 성능을 냈지만, content code와 style code가 entangle하게 학습되는 경향이 있었다. (이미지가 structure consistency를 잃어가며 생성됨)
- 저자들은 self-supervision에 기초하여 content code와 style code를 dientangle하게 학습할 수 있도록
code consistency loss를 제안하였다.
또한, 이전 연구들은 style transfer시 특정 region만 control을 하려면, semantic mask가 필요했다.
- 본 연구는 semantic label 없이 특정 영역의 style을 바꿀 수 있도록
content alignment loss를 제안하였다. 이 loss를 통해 foreground area는 transferred image와 비슷하게 유지하면서 background image만을 변하게 만들 수 있다.
Method

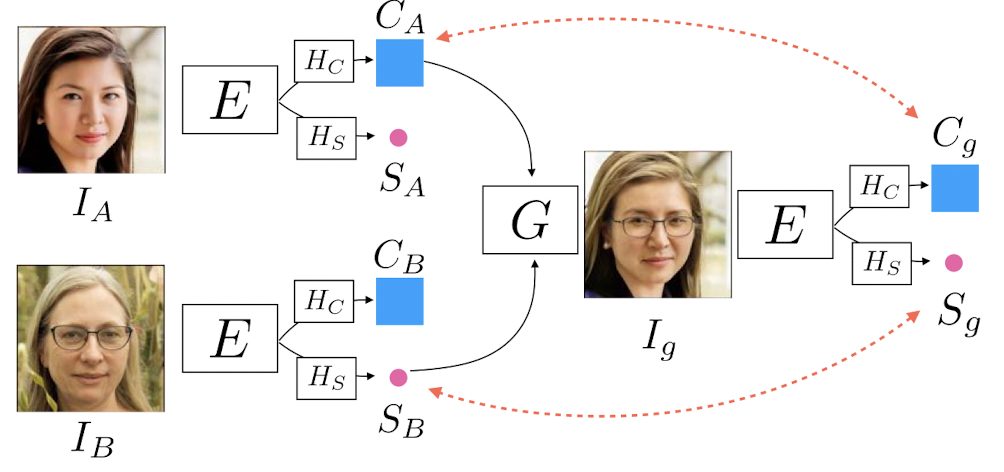
- 먼저 encoder $E$ 를 사용하여 input image $I$ 를 deep feature map $e$ 로 projection 시킨 후
- 2개의 sub-networks, $H_c, H_s$ 를사용하여 이 feature map을 content code와 style code로 변환
- $H_c$ : 여러개의 normal convolution으로 구성되어있으며 $C$ 의 channel을 compress
- $H_s$ : down-sampling convolutions, $S$ 를 vector화하여 structural information을 제거
- 이미지 생성 $I_g = G(C,S)$
- Generator
- Image reconstruction: $I_{A \rightarrow A}=G\left(C_{A}, S_{A}\right)$
- recon loss
- style transfer: $I_{A \rightarrow B}=G\left(C_{A}, S_{B}\right)$
- transferred result $I_{A \rightarrow B}$ 는 target image(GT)가 없음
- SwapAuto 에서는 co-occurrence discriminator $D_{co}$ 를 사용하여 randomly cropped image patch를 판별
-
adv loss
\[\begin{aligned}\mathcal{L}_{\mathrm{adv}} &=\mathbb{E}_{D}\left[-\log \left(D\left(I_{A \rightarrow A}\right)\right)\right]+\mathbb{E}_{D}\left[-\log \left(D\left(I_{A \rightarrow B}\right)\right)\right] \\&+\mathbb{E}_{D_{\text {co }}}\left[-\log \left(D_{\mathrm{co}}\left(\operatorname{crop}\left(I_{A \rightarrow B}\right), \operatorname{crop}\left(I_{B}\right)\right)\right)\right]\end{aligned}\]
- Image reconstruction: $I_{A \rightarrow A}=G\left(C_{A}, S_{A}\right)$
- Generator
Code consistency loss for code disentanglement

Swap AE에서는 style code를 vector화함으로써 spatial information을 제거하고자 하였다. 그러나 image의 structure가 style reference image를 따라가는 현상이 있다.(Fig 3)
- style code가 structure information도 같이 embedding하고 있는, disentanglement한 현상
Code Consistency Loss
content consistency loss와style consistency loss- MUNIT의 content recon loss 와 style recon loss랑 똑같은듯?
- Encoder는 fake image와 real image에 대해 robust하다고 가정하며, 이를 위해 encoder를 optima까지 먼저 학습시킨다.
Content alignment loss for region-wise stylization



- 이미지의 align이 안 맞거나 두 이미지간의 외형이 너무 다르면 잘 안 될 것 같다..
Results

Interpolation

Cross Domain Style Transfer

- 두 도메인에 대해서 joint하게 dataset을 합친 다음 모델을 학습
댓글남기기